V porovnaní s tradičnými relačnými databázami sú databázy noSQL vhodnejšie pre dynamické poskytovanie, horizontálne škálovanie, zlepšenie výkonu a na nasadenie do cloudu. Na základe týchto skutočností si v tomto článku ukážeme ako migrovať databázu MySQL do databázy MongoDB a jej nasadenie do cloudu.
MongoDB je podľa Google trendov najobľúbenejšou nerelačnou databázou vďaka vlastnostiam zahŕňajúcim jednoduchosť, agilitu a rozsiahlu podporu pre vývojárov. MongoDB na rozdiel od MySQL ukladá tabuľky v JSON kolekciách v binárnom súbore s názvom BSON (Binary JSON). Kódovanie BSON rozširuje zastúpenie JSON o ďalšie dátové typy ako int, long a floating point. Základné rozdiely medzi bežnými konceptami MySQL a MongoDB vidíme v nasledujúcej tabuľke:

Na mapovanie MySQL tabuliek do separátnych JSON domentov využijeme script implementovaný v jazyku Phyton.
Inštalácia Phyton 3.6
Pre spustenie scriptu je potrebná inštalácia poslednej stabilnej verzie Phyton. Pre stiahnutie je nutné navštíviť oficiálnu stránku Phyton. Postup inštalácie je taktiež dostupný na oficiálnych stránkach. Pri inštalácii je potrebné sa uistiť, že políčko Add Phyton 3.6 to Path je zaškrtnuté.
Spustenie migračného scriptu
Pred spustením scriptu skontrolujeme, či sa súbor Phyton27 nachádza na disku C, otvoríme príkazový riadok a identifikujeme cestu, kde sa migračný script nachádza. V rovnakom priečinku sa musí nachádzať aj .sql súbor, ktorý ideme migrovať. Ak je databáza príliš veľká, môžeme ju rozdeliť na viacero .sql súborov, ktoré budeme postupne migrovať do JSON dokumentov. Script spustíme v príkazovom riadku nasledujúcim príkazom:
C:\Python27\python.exe C:\path to script\mySQLtoMongoDB.py
Proces migrácie údajov sa začne a postupne sú z každej tabuľky zo súboru .sql generované JSON dokumenty.
Vytvorenie inštancie pre cloud
Inštanciu pre cloud vytvoríme pomocou ObjectRocket, kde sa najprv zaregistrujeme a pridáme informácie pre platby. ObjectRocket poskytuje na mesiac skúšobnú inštanciu zadarmo. Pre vytvorenie inštancie si vyberieme, pre akú databázu ju potrebujeme, v tomto prípade MongoDB a zvolíme typ databázy. Na výber máme MongoDB Shared a MongoDB Replica Set. Ďalej zvolíme zónu, ktorá vyhovuje databáze a dátový plán. Je možné zvoliť aj službu šifrovania dát a zálohu pre inštanciu. V ďalšom kroku vytvoríme ACL (Access Control List), ktorý limituje pripojenie IP adries k inštancii. Pridáme našu aktuálnu IP adresu a definitívne vytvoríme inštanciu.
Inštalácia Studio 3T
Studio 3T predstavuje GUI pre prácu s MongoDB. Je nutné si ho nainštalovať pre vytvorenie databázy a prácu s ňou. Je to platený softvér, ktorý je však možné využívať na mesiac zadarmo. Stiahnuť si ho môžte tu.
Vytvorenie MongoDB a načítanie JSON dokumentov
Vrámci vytvorenej inštancie sú dostupné viaceré operácie, základnou je vytvorenie databázy. Na jej vytvorenie poskytneme meno databázy, meno používateľa a heslo. Tieto informácie sú nutné pre pripojenie k databáze pomocou nástroja Studio 3T. V záložke Connect sa nachádzajú pripojovacie reťazce pre pripojenie k inštancii:
mongodb://YOUR_USERNAME:YOUR_PASSWORD@lon5-c11-0.mongo.objectrocket.com:43448,lon5-c11-1.mongo.objectrocket.com:43448,lon5-c11-2.mongo.objectrocket.com:43448/YOUR_DATABASE_NAME?replicaSet=80894285874449759d9e429e39ef0338
Otvoríme Studio 3T a klikneme na tlačidlo Connect, potom na tlačidlo From URI, skopírujeme pripojovací reťazec a vložíme meno používateľa a heslo, ktoré sme si zvolili pri vytváraní databázy.
Po zadaní pripojovacieho reťazca vidíme zobrazenú množinu replík vytvorenej inštancie. Údaje uložíme a pripojíme sa ku cloudu. Z cloudu je automaticky zobrazená vytvorená databáza, do ktorej budeme importovať JSON dokumenty. Z možností pri tejto databáze vyberieme importovať kolekcie a vyberieme JSON súbory, ktoré chceme importovať. Táto operácia môže trvať dlhý čas v závislosti od množstva kolekcií. Po importovaní údajov sa zmení stav databázy aj v nástroji ObjectRocket, kde je zobrazený počet kolekcií databázy, počet objektov, veľkosť dát atď.
Modelovanie vzťahov v MongoDB
MongoDB nepodporuje funkciu JOIN. Preto pre správne fungovanie MongoDB a prospešné využívanie modelu dokumentu vytvárame z dvoch a viacerých kolekcií, ktoré obsahujú nejaký vzťah, jednu kolekciu. Takúto kolekciu nevytvárame v prípade prekročenia maximálnej veľkosti dokumentu, a to 16MB. Tento model mapovania vzťahov sa nazýva vstavaný model. Pre mapovanie využívame IntelliShell v nástroji Studio 3T, ktorý je určený na spúšťanie scriptov v jazyku JavaScript. Na budovanie vstavaného modelu implementujeme funkciu aggregate().
db.name_of_collection.aggregate([
{
$lookup: {
from: "name_of_collection2",
localField: "common_field1",
foreignField: "common_field2",
as: "name_of_new_field",
}},
{
$out: "name_of_aggregate_collection"
}
]}
Týmto spôsobom agregujeme všetky kolekcie na to určené. Pôvodné kolekcie vymažeme, aby sme zbytočne neplytvali úložiskom. Tento spôsob modelovania vzťahov vytvára dáta ľahko dostupnými a udržiavateľnými. Po implementovaní agregácie budú dokumenty mapované rovnako ako na nasledujucom obrázku:
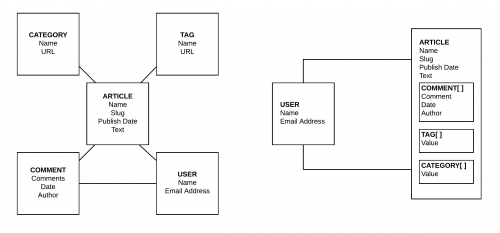
Dotaz na získanie informácií zo vstavaného modelu je nasledovný:
db.name_of_collection.findOne({“field”: “id”},{“name_of_new_field”:1});
Modelovanie referencií nahrádza vstavaný model kolekcií, keď ho nie je možné použiť. Každý dokument v kolekcii má svoje vlastné _id, ktoré môžme priradiť k inému dokumentu, a tak vytvoriť medzi nimi vzťah. Referencie modelujeme nasledujúcim príkazom:
db.name_of_collection.update({“_id”: ObjectId(“id”)}, {$push: {“name_of_new_field”: ObjectId(“id”)}});
Na dotazovanie referencií sa používajú dva príkazy, a to:
var result = db.name_of_collection.findOne({“field”:”id”},{“name_of_new_field”:1});
var indexes = db.name_of_collection2.find({“_id”:{“$in”:result[“name_of_new_field”]}});
Po namodelovaní všetkých vzťahov v MongoDB databáze je pripravená na používanie a je možné ju integrovať k aplikácii.