V článku sa naučíte vytvárať dátové tabuľky v jazyku R a prostredníctvom niektorých funkcii ich efektívne spracovávať. Ukážeme si tvorbu diagramov (grafov) z dátových tabuliek len s pomocou minimálneho množstva kódu a bohaté vizualizačné možností, ktoré ponúka R.
Úvod do R
Na jednoduchú manipuláciu dátových štruktúr ako sú zoznamy, tabuľky či matice sa môže využívať programovací jazyk R. Dokáže štatisticky spracovávať rôzne dátové štruktúry a následne ich vizualizovať napr. do grafickej podoby. Obsahuje veľké množstvo funkcii, ktoré uľahčujú a zefektívňujú prácu s rôznymi podobami dát. Je šírený ako opensource projekt a preto ho môže využívať každý podľa ľubovôle.
Prečo práve jazyk R?
Jazyk R dokáže jednoducho a rýchlo spracovávať rôzne dátové štruktúry (napr. vektory, zoznamy, tabuľky atď.), vykonávať štatistické výpočty a grafický vizualizovať rôzne dáta. Tieto tri možností patria medzi hlavne predností jazyka R. Najväčšou konkurenciou R je jazyk Python. Väčšinu úkonov, ktorú zvládne R, dokáže aj Python. Takže ak použijete Python miesto R, tak by ste nemali byť sklamaní možnosťami, ktoré ponúka táto alternatíva.
Avšak nejaké rozdiely medzi R a Python sú. Odlišnosť môžeme vidieť napríklad pri implementácii získania súhrnnej štatistiky modelu, kde v Pythone musíme napísať 4 riadkový program, zatiaľ čo v R nám stačí zavolať funkciu summary(). R už od svojho vzniku bol uspôsobený na štatistické výpočty a grafický výstup, zatiaľ čo Python vznikol ako všestranný jazyk, ktorý dokáže veľa veci v mnohých oblastiach a až neskôr s pomocou knižníc sa rozširovali jeho možností v analýze dát. Preto má R náskok v poskytovaní možností v oblasti štatistického spracovania dát a mocné baličky ggvis, lattice, a ggplot2 s bohatým grafickým výstupom ho robí lídrom v oblastí analýzy dát a optimalizácie výpočtových operácii. Ak to myslíte vážne so štatistickým spracovaním dát, tak vám odporúčam naučiť syntax jazyka R pre jeho skutočne efektívny zápis a bohatšie štatistické a vizualizačné možností oproti alternatíve.
Vývojové prostredie pre R
Jazyk R vieme spustiť v príkazovom riadku, ale existujú aj celé vývojové prostredia s užitočnými funkciami ako zvýraznenie syntaxe, jednoduché vyhľadávanie v kóde a podpora debuggera. Jedným z najznámejších a obľúbených vývojových prostredí je RStudio. Obsahuje mnoho užitočných funkcii, ktoré uľahčujú prácu pri vyvíjaní programov. K dispozícii je zdarma dostupný pre operačné systémy Windows, Linux aj Mac na oficiálnej stránke projektu RStudio.
Základná práca s tabuľkami
Hello world
Než sa dostaneme k dátovým tabuľkám, tak je dôležité si vysvetliť základnú syntax, s ktorou sa stretneme snáď v každom programe. Ako nám tradícia tvorby tutoriálov káže, vytvoríme si prvý program Hello world. Pôjde o jednoduchý program, ktorý má za úlohu vypísať reťazec Hello world. Vyskúšame si tak priradenie hodnoty do nejakej premennej a jej následne vypísanie.
retazec <- "Hello world"
print(retazec)
Výstup programu bude vyzerať následovne:
[1] "Hello world"
Ak chceme spustiť program Hello world vo vývojovom prostredí RStudio, musíme označiť kód napísaný v editore a až tak môžeme kliknúť na tlačítko Run.

V konzole by sme mali vidieť výstup programu. Znak > reprezentuje riadok v konzole a nemá vplyv na beh programu.
Vráťme sa späť k programu Hello world. Premenná získa určitú hodnotu po použití priraďovacieho príkazu <-. Môžte použiť ako priraďovací príkaz aj =. Ktoré z priradení použijete je len vo vašej réžii, pretože funkcionalitou sa nelíšia. Na vypísanie hodnoty sme si zobrali generickú funkciu print() a jej argumentom je reťazec, ktorý chceme vypísať.
Skúsme modifikovať program a namiesto reťazca vypíšme číslo.
cislo <- 1025
print(cislo)
[1] 1025
Jednoduché však? Čo ak by sme chceli vypísať naraz reťazec aj číslo? V tvare napr. Dnes je v Košiciach 12°C. s tým, že číslo 12 nebude súčasťou reťazca, ale bude premennou. Túto úlohu skúsme vyriešiť s pomocou funkcie sprintf(), ktorá formátuje reťazce spôsobom známym v jazyku C.
teplota <- 12
sprintf("Dnes je v Košiciach %d °C.",teplota)
[1] "Dnes je v Košiciach 12 °C."
Pre tých, čo nemajú skúsenosť s formátovaním reťazcov v jazyku C, tak znak % označujeme ako špecifikátor formátu. Za špecifikátorom formátu nasleduje typ premennej a v našom prípade je to znak d označujúci celé číslo. Takto šikovne vieme označiť premennú v reťazci. Ak by sme miesto celého čísla chceli znak, tak napíšeme %c alebo ak reťazec, tak %s. Viac o možnostiach špecifikátora formátu sa dočítame v anglickom tutoriáli.
Tvorba dátových tabuliek
Medzi najpoužívanejšie dátové štruktúry patrí dátová tabuľka. Je cenená pre svoje univerzálne vlastnosti efektívneho spracovania veľkého množstva dát. Ak chceme v jazyku R vytvoriť tabuľku ako dátovú štruktúru, využijeme nato základnú funkciu jazyka R, data.frame(). Dátová tabuľka sa bude skladať z vektorov rovnakej dĺžky s naplnenými dátami. S tvorbou vektorov nám pomôže generická funkcia c(). Hodnoty, ktoré budú naše vektory obsahovať, doplníme ako argumenty funkcie c().
prvyVektor <- c(30,20,18,17,38,45)
druhyVektor <- c(20,15,21,24,14,25)
tabulka <- data.frame(prvyVektor,druhyVektor)
print(tabulka)
prvyVektor druhyVektor
1 30 20
2 20 15
3 18 21
4 17 24
5 38 14
6 45 25
Vytvorili sme dva vektory o veľkostí 6 a nasekali sme ich do našej dátovej tabuľky vytvorenej s pomocou funkcie data.frame(). Generická funkcia print() nám dátovú tabuľku vypíše.
Skúsme pomenovať naše dva vektory.
prvyVektor <- c(30,20,18,17,38,45)
druhyVektor <- c(20,15,21,24,14,25)
tabulka <- data.frame(vyska=prvyVektor,sirka=druhyVektor)
print(tabulka)
vyska sirka
1 30 20
2 20 15
3 18 21
4 17 24
5 38 14
6 45 25
Prvý stĺpec dátovej tabuľky má názov vyska a druhý sirka. Teraz nám začína byť jasnejšie, čo tie dáta znamenajú. Pomenujme aj riadky.
prvyVektor <- c(30,20,18,17,38,45)
druhyVektor <- c(20,15,21,24,14,25)
tabulka <- data.frame(vyska=prvyVektor,sirka=druhyVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier"))
print(tabulka)
vyska sirka
pracka 30 20
zehlicka 20 15
pocitac 18 21
radio 17 24
stol 38 14
tanier 45 25
Na pomenovanie riadkov sme využili argument row.names. Teraz už vieme, ktorým veciam bola nameraná výška a šírka. Pridajme do našej tabuľky ďalší stĺpec predstavujúci nameranú hĺbku domácich spotrebičov.
prvyVektor <- c(30,20,18,17,38,45)
druhyVektor <- c(20,15,21,24,14,25)
tabulka <- data.frame(vyska=prvyVektor,sirka=druhyVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier"))
tabulka$hlbka = c(5,6,2,10,11,8)
print(tabulka)
vyska sirka hlbka
pracka 30 20 5
zehlicka 20 15 6
pocitac 18 21 2
radio 17 24 10
stol 38 14 11
tanier 45 25 8
Vektor hodnôt sme novému stĺpcu priradili takýmto zápisom: tabulka$hlbka. Práve znak $ nám umožní pristúpiť k nejakému stĺpcu v dátovej tabuľke.
Ak vieme pridávať stĺpce, tak ich vieme aj mazať. Vymažme druhý stĺpec s pomocou hodnoty NULL.
prvyVektor <- c(30,20,18,17,38,45)
druhyVektor <- c(20,15,21,24,14,25)
tabulka <- data.frame(vyska=prvyVektor,sirka=druhyVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier"))
tabulka$hlbka = c(5,6,2,10,11,8)
tabulka$sirka = NULL
print(tabulka)
vyska hlbka
pracka 30 5
zehlicka 20 6
pocitac 18 2
radio 17 10
stol 38 11
tanier 45 8
Vypíšme len prvý stĺpec tabuľky.
prvyVektor <- c(30,20,18,17,38,45)
druhyVektor <- c(20,15,21,24,14,25)
tabulka <- data.frame(vyska=prvyVektor,sirka=druhyVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier"))
tabulka$hlbka = c(5,6,2,10,11,8)
print(tabulka$vyska)
[1] 30 20 18 17 38 45
Rovnako nie je pre nás problém vypísať len riadok pomenovaný ako pocitac.
prvyVektor <- c(30,20,18,17,38,45)
druhyVektor <- c(20,15,21,24,14,25)
tabulka <- data.frame(vyska=prvyVektor,sirka=druhyVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier"))
tabulka$hlbka = c(5,6,2,10,11,8)
print(tabulka['pocitac',])
vyska sirka hlbka
pocitac 18 21 2
Ak chceme spojiť dve tabuľky cez stĺpce, využijeme funkciu cbind(). Podmienkou pre úspešné spojenie je rovnaký počet riadkov v prvej aj druhej tabuľky.
prvyVektor <- c(30,20,18,17,38,45)
druhyVektor <- c(20,15,21,24,14,25)
tretiVektor <- c(5,6,2,10,11,8)
tabulka1 <- data.frame(vyska=prvyVektor,sirka=druhyVektor, hlbka=tretiVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier"))
prvyVektor <- c(25,50,12,10,44,22)
druhyVektor <- c(26,25,22,21,24,21)
tabulka2 <- data.frame(hmotnost=prvyVektor,teplota=druhyVektor)
tabulka <-cbind(tabulka1, tabulka2)
print(tabulka)
vyska sirka hlbka hmotnost teplota
pracka 30 20 5 25 26
zehlicka 20 15 6 50 25
pocitac 18 21 2 12 22
radio 17 24 10 10 21
stol 38 14 11 44 24
tanier 45 25 8 22 21
Tak ako vieme spojiť tabuľky cez stĺpce, môžme aj prostredníctvom riadkov. Počet stĺpcov a ich názvy sa musia zhodovať u obidvoch tabuliek, ktoré máme v pláne spojiť.
prvyVektor <- c(30,20,18,17,38,45)
druhyVektor <- c(20,15,21,24,14,25)
tretiVektor <- c(5,6,2,10,11,8)
tabulka1 <- data.frame(vyska=prvyVektor,sirka=druhyVektor, hlbka=tretiVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier"))
prvyVektor <- c(11,25)
druhyVektor <- c(24,32)
tretiVektor <- c(8,4)
tabulka2 <- data.frame(vyska=prvyVektor,sirka=druhyVektor, hlbka=tretiVektor, row.names = c("susicka","lampa"))
tabulka <-rbind(tabulka1, tabulka2)
print(tabulka)
vyska sirka hlbka
pracka 30 20 5
zehlicka 20 15 6
pocitac 18 21 2
radio 17 24 10
stol 38 14 11
tanier 45 25 8
susicka 11 24 8
lampa 25 32 4
Užitočné nástroje pre efektívnu prácu s dátovými tabuľkami
Medzi užitočné funkcie v R patria nrow() a sum(). Skúsme na základe týchto dvoch funkcii vypočítať priemer hodnôt stĺpca hlbka.
prvyVektor <- c(30,20,18,17,38,45,11,25)
druhyVektor <- c(20,15,21,24,14,25,24,32)
tretiVektor <- c(5,6,2,10,11,8,8,4)
tabulka <- data.frame(vyska=prvyVektor,sirka=druhyVektor, hlbka=tretiVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier","susicka","lampa"))
print(sum(tabulka$hlbka)/nrow(tabulka))
[1] 6.75
Funkcia sum() nám sčíta všetky hodnoty v konkrétnom stĺpci a keďže počet hodnôt sa rovná počtu riadkov tabuľky, tak využijeme funkciu nrow() na dopočítanie priemeru.
Spôsob výpisu priemeru stĺpca hlbka sme vybrali nešťastne. Používateľ, ktorý by si spustil program, nevie čo daná hodnota 6.75 znamená. Aj keď poznáme funkciu sprintf() na pohodlné vypísanie reťazca s premennými, ale ukážme si alternatívu v kombinácii použitia funkcie paste() a print().
prvyVektor <- c(30,20,18,17,38,45,11,25)
druhyVektor <- c(20,15,21,24,14,25,24,32)
tretiVektor <- c(5,6,2,10,11,8,8,4)
tabulka <- data.frame(vyska=prvyVektor,sirka=druhyVektor, hlbka=tretiVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier","susicka","lampa"))
print(paste("Priemer hodnot v stlpci hlbka:", sum(tabulka$hlbka)/nrow(tabulka)))
[1] "Priemer hodnot v stlpci hlbka: 6.75"
Výstup funkcie paste() je vektor znakov, ktorý vznikne po zlúčení rôznych reťazcov a premenných rôzneho typu. O následne vypísanie vektora znakov sa postará už nám veľmi dobré známa funkcia print().
Často sa môžeme stretnúť s tým, že potrebujeme si utriediť hodnoty v stĺpci a s tým, aby aj riadky sa premiestnili spoločné s utriedenou hodnotou. Chceme sa tak vyhnúť tomu, aby príslušný riadok získal iné namerané dáta z iných riadkov. V nasledovnom programe vytriedime riadky podľa stĺpca sirka.
prvyVektor <- c(30,20,18,17,38,45,11,25)
druhyVektor <- c(20,15,21,24,14,25,24,32)
tretiVektor <- c(5,6,2,10,11,8,8,4)
tabulka <- data.frame(vyska=prvyVektor,sirka=druhyVektor, hlbka=tretiVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier","susicka","lampa"))
tabulka <- tabulka[order(tabulka$sirka),]
print(tabulka)
vyska sirka hlbka
stol 38 14 11
zehlicka 20 15 6
pracka 30 20 5
pocitac 18 21 2
radio 17 24 10
susicka 11 24 8
tanier 45 25 8
lampa 25 32 4
Vytriedili sme riadky od najmenšej hodnoty po najväčšiu. Ak chceme opačne triedenie, zmeňme predvolené nastavený logický argument decreasing z FALSE na TRUE.
prvyVektor <- c(30,20,18,17,38,45,11,25)
druhyVektor <- c(20,15,21,24,14,25,24,32)
tretiVektor <- c(5,6,2,10,11,8,8,4)
tabulka <- data.frame(vyska=prvyVektor,sirka=druhyVektor, hlbka=tretiVektor, row.names=c("pracka","zehlicka","pocitac","radio","stol","tanier","susicka","lampa"))
tabulka <- tabulka[order(tabulka$sirka,decreasing = TRUE),]
print(tabulka)
vyska sirka hlbka
lampa 25 32 4
tanier 45 25 8
radio 17 24 10
susicka 11 24 8
pocitac 18 21 2
pracka 30 20 5
zehlicka 20 15 6
stol 38 14 11
Uloženie a načítanie dát
Organizovanie napr. nameraných dát do tabuľky by pre nás nemal predstavovať vážnejší problém. Vieme s pomocou šikovných funkcii rôzne manipulovať s dátami v tabuľkách. Ale ak skončí program, naše vytvorené a prípadne modifikované dáta sú rázom preč. Aby sme sa k modifikovaným dátam v tabuľke dostali neskôr, potrebujeme ich niekde uložiť, napr. do súboru. Pre tento účel využijeme funkciu write.table(). Najprv si pripravme dátovú tabuľku.
dopravnaNehodovost <- c(55,57,51,57,58,65,51,47,39,66)
teplota <- c(14,15,12,16,18,12,18,19,22,23)
tabulka <- data.frame(dopravnaNehodovost,teplota, row.names=c("1.tyzden","2.tyzden","3.tyzden","4.tyzden","5.tyzden","6.tyzden","7.tyzden","8.tyzden","9.tyzden","10.tyzden"))
print(tabulka)
dopravnaNehodovost teplota
1.tyzden 55 14
2.tyzden 57 15
3.tyzden 51 12
4.tyzden 57 16
5.tyzden 58 18
6.tyzden 65 12
7.tyzden 51 18
8.tyzden 47 19
9.tyzden 39 22
10.tyzden 66 23
Uložme dáta do súboru vo formáte CSV s pomocou základnej funkcie jazyka R write.table().
dopravnaNehodovost <- c(55,57,51,57,58,65,51,47,39,66)
teplota <- c(14,15,12,16,18,12,18,19,22,23)
tabulka <- data.frame(dopravnaNehodovost,teplota, row.names=c("1.tyzden","2.tyzden","3.tyzden","4.tyzden","5.tyzden","6.tyzden","7.tyzden","8.tyzden","9.tyzden","10.tyzden"))
write.table(tabulka,file = 'tabulka.csv', sep = ';')
Argumentom sep určíme separátor, ktorý bude rozdeľovať jednotlivé hodnoty v riadku. Názov súboru do ktorého chceme uložiť dáta, definujeme s pomocou argumentu file. Po úspešnom uložení dát do súboru ich budeme chcieť po nejakom čase opätovne načítať a ďalej s nimi pracovať. Na načítanie dátovej tabuľky použijeme funkciu read.table().
dopravnaNehodovost <- c(55,57,51,57,58,65,51,47,39,66)
teplota <- c(14,15,12,16,18,12,18,19,22,23)
tabulka <- data.frame(dopravnaNehodovost,teplota, row.names=c("1.tyzden","2.tyzden","3.tyzden","4.tyzden","5.tyzden","6.tyzden","7.tyzden","8.tyzden","9.tyzden","10.tyzden"))
write.table(tabulka,file = 'tabulka.csv', sep = ';')
tabulka <- read.table('tabulka.csv',sep = ';')
print(tabulka)
dopravnaNehodovost teplota
1.tyzden 55 14
2.tyzden 57 15
3.tyzden 51 12
4.tyzden 57 16
5.tyzden 58 18
6.tyzden 65 12
7.tyzden 51 18
8.tyzden 47 19
9.tyzden 39 22
10.tyzden 66 23
Práve s pomocou funkcie read.table() vieme načítať tabuľku a argument sep má ten istý význam ako sme ho uviedli pri funkcii write.table().
Čo ak chceme nejaké riadky pridať už do existujúcej tabuľky? Pohráme sa s argumentami funkcie write.table().
dopravnaNehodovost <- c(55,57,51,57,58,65,51,47,39,66)
teplota <- c(14,15,12,16,18,12,18,19,22,23)
tabulka <- data.frame(dopravnaNehodovost,teplota, row.names=c("1.tyzden","2.tyzden","3.tyzden","4.tyzden","5.tyzden","6.tyzden","7.tyzden","8.tyzden","9.tyzden","10.tyzden"))
write.table(tabulka,file = 'tabulka.csv', sep = ';')
doplnenie1 <- c(47,41,34,54,45)
doplnenie2 <- c(21,22,24,18,17)
doplnenieRiadkov <- data.frame(doplnenie1,doplnenie2,row.names = c("11.tyzden","12.tyzden","13.tyzden","14.tyzden","15.tyzden"))
write.table(doplnenieRiadkov,file = 'tabulka.csv', sep = ';', col.names = FALSE, append = TRUE)
tabulka <- read.table('tabulka.csv',sep = ';')
print(tabulka)
dopravnaNehodovost teplota
1.tyzden 55 14
2.tyzden 57 15
3.tyzden 51 12
4.tyzden 57 16
5.tyzden 58 18
6.tyzden 65 12
7.tyzden 51 18
8.tyzden 47 19
9.tyzden 39 22
10.tyzden 66 23
11.tyzden 47 21
12.tyzden 41 22
13.tyzden 34 24
14.tyzden 54 18
15.tyzden 45 17
Prvý zápis tabuľky do súboru už poznáte, ale pri druhom zápise pribudli dva argumenty, menovite col.names a append. Argumentom append nastavený na TRUE funkcii write.table() povieme, že nemá novou tabuľkou prepisovať existujúcu tabuľku. Takže miesto prepisu tabuľky dôjde k tomu, že prvý riadok tabuľky začne tam, kde končí posledný riadok už existujúcej tabuľky. Pri argumente col.names sme zvolili možnosť FALSE, pretože stĺpce už sú pomenované a nová tabuľka doplní novými riadkami existujúcu tabuľku. Rovnako musí sedieť počet stĺpcov novej tabuľky s tou existujúcou, inak sa objaví chybová hláška.
Vizualizácia dátových tabuliek
Predstavte si, že máte dátovú tabuľku so stovkami až tisíckami riadkami a potrebujete zistiť v dátach ich vzájomne vzťahy či vypozorovať trendy v hodnotách. Bolo by veľmi nepraktické a časovo náročné skúmať všetky tie riadky a vytvárať si o dátach nejaký obraz. Preto sa pre výrazné zjednodušenie práce s dátami ujalo zobrazenie dát do grafickej podoby v podobe diagramov.
Čiarový diagram
Prvý typ diagramu, ktorý si implementujeme v R je čiarový diagram. Tento typ diagramu nám umožňuje sledovať zmeny vybranej kategórie hodnôt (napr. teplota, tlak, hmotnosť atď) v čase. Pre začiatok si vytvorme dátovú tabuľku s troma stĺpcami.
teplota <- c(21,20,18,17,15,13,22,23,24,20)
vlhkostVzduchu <- c(70,65,78,45,54,63,41,87,82,58)
rychlostVetra <- c(32,44,25,17,10,5,36,45,56,59)
tabulka <- data.frame(teplota, vlhkostVzduchu, rychlostVetra, row.names=c("1.den","2.den","3.den","4.den","5.den","6.den","7.den","8.den","9.den","10.den"))
write.table(tabulka,file = 'tabulka.csv', sep = ';')
Dátovú tabuľku sme naplnili fiktívnymi dátami reprezentujúce poveternostné podmienky v Košiciach za 10 dňové obdobie. Teplota je vyjadrená v stupňoch Celzia °C, rýchlosť vetra v km/h a vlhkosť vzduchu v relatívnej vlhkostí %.
Na vytvorenie čiarového diagramu využijeme generickú funkciu plot().
data <- read.csv("tabulka.csv",sep=';')
png(file = "multiple_line_chart.png")
plot(data$teplota, type = "l", col = "red", xlim = c(1,10), ylim = c(1,100), xlab = "Days", ylab = "Values")
dev.off()
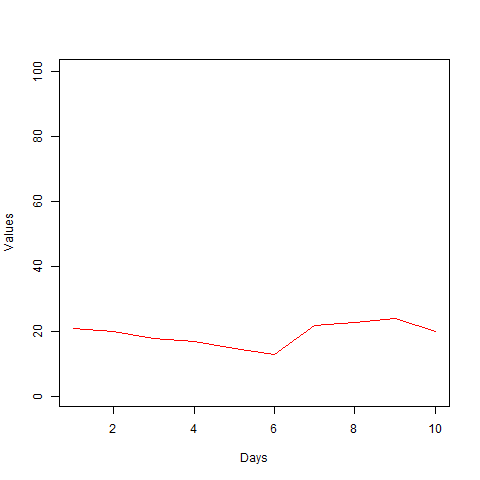
Časový priebeh sledovaných hodnôt je vyjadrený v x-ovej osi a rozsah hodnôt sledovanej kategórie dát je vyjadrená v y-ovej osi. Rozsahy jednotlivých osi určíme s pomocou argumentov xlim a ylim a o ich pomenovanie sa postarajú argumenty xlab a ylab. Dáta, ktoré sa majú sledovať v čase sme definovali v prvom argumente vo forme data$teplota, čo nie je nič iné, než náš pomenovaný stĺpec teplota z dátovej tabuľky. V argumente type nastavíme vykreslenie hodnôt ako čiaru.
Grafické zariadenie, ktoré nám uloží graf do PNG formátu, otvoríme (zapneme) s pomocou funkcie png(). Ak počas zapnutého grafického zariadenia zavoláme funkciu, ktorá vizualizuje dáta napr. plot(), barplot(), pie() atď., uloží sa nám graf do PNG formátu. To znamená, že ak po funkcii png() zavoláme napr. dva krát funkciu plot(), vygenerujú sa nám dva grafy. Po uložení obrázka grafické zariadenie vypneme zavolaním funkcie dev.off(). Bez vypnutia grafického zariadenia nemôžeme otvoriť súbor formátu PNG, jedine ak reštartujeme alebo vypneme vývojové prostredie RStudio. Rovnako funkcia dev.off() rieši problém príliš veľa otvorených zariadení, kedy nám program vyhodí chybu. Preto je odporúčané vypínať grafické zariadenie, ak už sme s ním skončili prácu.
Na pomenovanie výsledných súborov využijeme argument file funkcie png(). Nie sme limitovaný len formátom PNG, môžme použiť aj funkcie bmp(), jpeg() či tiff().
Do diagramu pridajme ďalšie veličiny, ktoré máme prítomné v dátovej tabuľke uloženej v tabulka.csv.
data <- read.csv("tabulka.csv",sep=';')
png(file = "multiple_line_chart.png")
plot(data$teplota, type="l", col = "red", xlim = c(1,10), ylim = c(1,100), xlab = "Days", ylab = "Values")
lines(data$vlhkostVzduchu, type="l", col = "blue")
lines(data$rychlostVetra, type="l", col = "green")
dev.off()
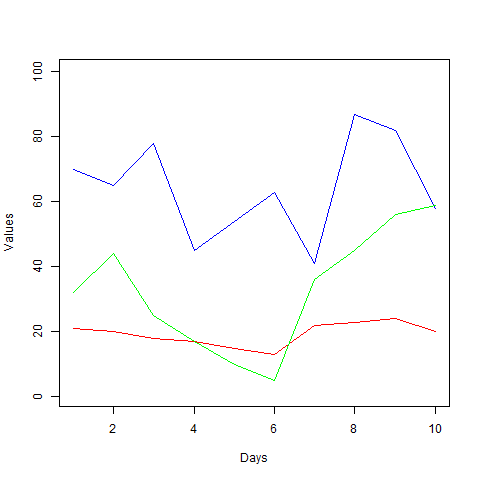
Samotná funkcia lines() nevytvára nový diagram, len pridáva nové informácie do existujúceho diagramu. Konkrétne sme pridali dve nové dátové kategórie vlhkostVzduchu a rychlostVetra zo stĺpcov našej dátovej tabuľky. Čiary vykresľujúce hodnoty sme farebne odlíšili s pomocou argumentu col. Zmeňme hodnotu argumentu type z l na o, čím sa zobrazia hodnoty ako čiary s prekrytými bodmi.
data <- read.csv("tabulka.csv",sep=';')
png(file = "multiple_line_chart.png")
plot(data$teplota, type = "o", col = "red", xlim = c(1,10), ylim = c(1,100), xlab = "Days", ylab = "Values")
lines(data$vlhkostVzduchu, type = "o", col = "blue")
lines(data$rychlostVetra, type = "o", col = "green")
dev.off()
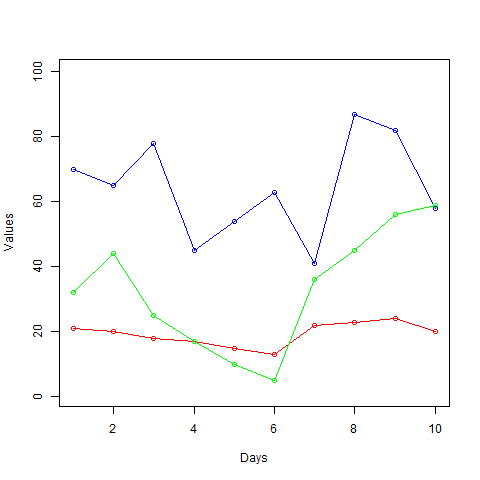
Ak by sme takýto graf ukázali náhodnému človeku, tak mnoho sa toho nedozvie, pretože chýba nápoveda ku vykresleným čiaram s prekrytými bodmi. Z dôvodu chýbajúcej nápovedy pridáme do grafu legendu.
data <- read.csv("tabulka.csv",sep=';')
png(file = "multiple_line_chart.png")
plot(data$teplota, type = "o", col = "red", xlim = c(1,10), ylim = c(1,100), xlab = "Days", ylab = "Values")
lines(data$vlhkostVzduchu, type = "o", col = "blue")
lines(data$rychlostVetra, type = "o", col = "green")
legend("top",legend=c("Teplota (°C)","Vlhkosť vzduchu (%)", "Rýchlosť vetra (km/h)"),pch=21,col=c("red", "blue","green"),bty="n",cex=1,text.col=c("red", "blue","green"),lty=1,lwd=1)
dev.off()
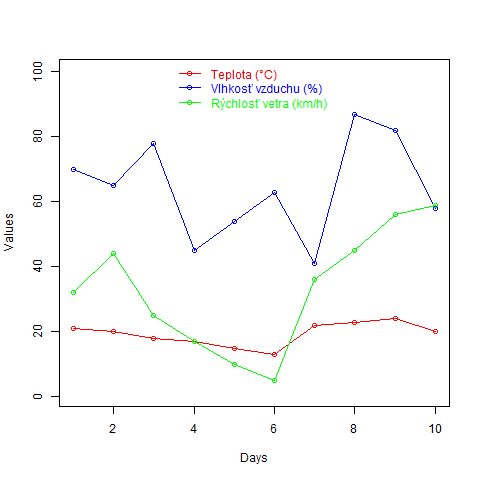
Argumenty x a y funkcie legend() sú súradnice v grafe za účelom umiestnenia legendy na určité miesto. V našom prípade nemáme číselné súradnice, ale použili sme špeciálne slovo top, čo zapríčiní umiestnenie legendy do hornej častí grafu. Názvy vykreslených čiar zadefinujeme v argumente legend a samotnú značku čiary vytvoríme v argumente lty a typ čiary určíme hodnotou 1. Krúžok do značky čiary pridáme v argumente pch. Funkcia legend() má na výber veľa rôznych argumentov, preto je odporúčané si preštudovať manuál k nej.
Stĺpcový diagram
Stĺpcový graf podobne ako čiarový graf, sleduje zmenu hodnôt v čase (najtypickejšia aplikácia), avšak hodnoty nie sú vyjadrené napr. ako body prepojené čiarou, ale ako stĺpce. Na tvorbu stĺpcového diagramu využijeme funkciu barplot().
data <- read.csv("tabulka.csv",sep=';')
png(file = "bar_chart.png")
barplot(data$teplota, main="Distribúcia teplôt počas 10 dňového obdobia ", xlab="Days", ylab="Temperature (°C)", col = "blue",ylim = c(0,25))
dev.off()
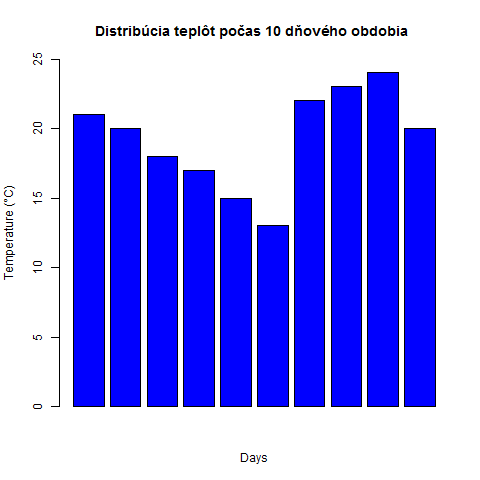
Argumentom ylim zadefinujeme rozsah y-ovej osi. Názov grafu píšeme v argumente main. Farbu stĺpcov sme určili v argumente col.
Funkcia barplot() umožňuje vytvárať aj horizontálne grafy. To sú grafy, ktorých stĺpce sú obrátene v smere x-ovej osi.
data <- read.csv("tabulka.csv",sep=';')
png(file = "bar_chart.png")
barplot(data$teplota, main="Distribúcia teplôt počas 10 dňového obdobia ", xlab="Temperature (°C)", ylab="Days", col = "blue", xlim = c(0,25),horiz = TRUE, names.arg=c("1", "2", "3","4","5","6","7","8","9","10"))
dev.off()
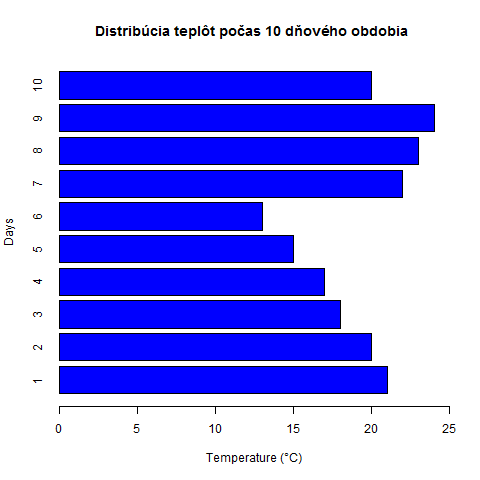
Horizontálny graf vytvoríme tak, že nastavíme argumentu horiz pravdivostnú hodnotu TRUE. Lenže zmenou grafu z vertikálneho na horizontálny sa nám automatický nepriradia názvy osi správne. Treba sa pohrať s argumentmi xlab, ylab a miesto argumentu ylim použiť argument xlim. Do grafu sme pridali aj pomenovanie jednotlivých stĺpcov s pomocou argumentu names.arg.
Koláčový diagram
Koláčový resp. kruhový diagram sa využíva na proporcionálne vyjadrenie daných hodnôt z celého súboru dát. Príkladom koláčového diagramu môže byť, že chceme proporcionálne vizualizovať početnosť ľudí, ktorí vyštudovali ako najvyššie dosiahnuté vzdelanie základnú školu, strednú školu, gymnázium alebo vysokú školu. Dáta sa proporčné rozdelia na častí koláča podľa veľkostí danej hodnoty. Celý koláč potom predstavuje sumu všetkých hodnôt, čiže v našom prípade všetky odpovede na dosiahnuté vzdelanie.
Funkcia pie() sa nám postará o vytvorenie koláčového grafu. Vytvoríme si novú dátovú sadu, pretože dáta z dátovej tabuľky tabulka.csv sa k vizualizácii do koláčového grafu nehodia.
png(file = "pie_chart.png")
pie(c(21,52,78,55,92,24), labels = c("A","B","C","D","E","Fx"), main="Hodnotenie študentov z predmetu Matematická analýza I.")
dev.off()
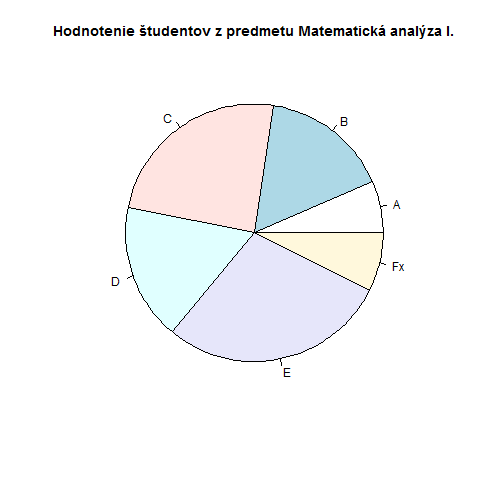
Na vytvorenie plnohodnotného koláčového grafu potrebujeme max. 3 riadky kódu. Vidíme v praxi efektívnosť zápisu v jazyku R. V prvom argumente definujeme jednotlivé dáta a v druhom argumente ich pomenovanie. Názov grafu pohodlne špecifikujeme v argumente main.
Pridajme do grafu numerické vyjadrenie proporčného rozdelenia hodnôt. Rovnako implementujme do grafu sýtejšie farby.
data <- c(21,52,78,55,92,24)
png(file = "pie_chart.png")
pie(data, labels = paste(c("A","B","C","D","E","Fx")," - ", data, " št."), main="Hodnotenie študentov z predmetu Matematická analýza I.",col = rainbow(length(data)))
dev.off()
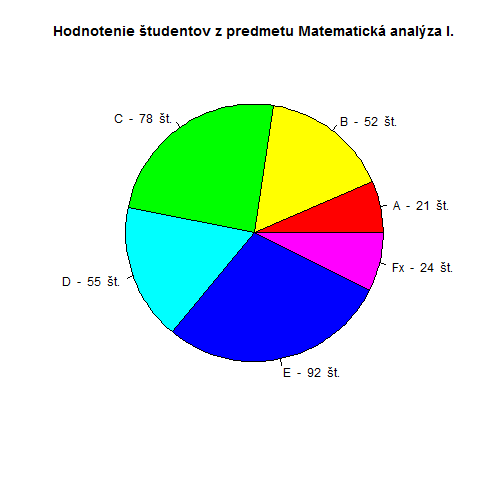
Do argumentu labels sme pridali reťazec " - “, hodnoty našej dátovej sady a ukončíme to druhým reťazcom ” št.". Funkcionalita argumentu labels je principiálne jednoduchá, aj keď sa to na prvé pozretie nezdá. V podstate robí to, že podľa množstva proporcionálnych rozdelení grafu vypíše každej častí pomenovanie definované ako hodnota argumentu. Ak je v hodnote argumentu labels vektor, tak v každej častí koláča vypíše nasledujúci prvok vektora. Ak nejde o vektor, tak sa stále vypíše napr. ten istý reťazec. Čo sa týka pridania sýtejších farieb, použili sme funkciu rainbow(). Táto funkcia vracia n počet farieb z preddefinovanej farebnej palety. V našom prípade je n počet hodnôt našej dátovej sady.
Bodový diagram
Posledný graf u ktorého si ukážeme implementáciu v R je bodový graf. Tento typ diagramu sa využíva pri vizualizácii vzájomného vzťahu dvoch kategórii premenných. V x-ovej osi už nemáme napr. čas alebo inú kategóriu, ale vlastný súbor dát tak ako v y-ovej osi. Na vytvorenie bodového grafu nebudeme potrebovať nové funkcie, vystačíme s tými, ktoré poznáme.
data <- read.csv("tabulka.csv",sep=';')
png(file = "scatter_plot.png")
plot(data$teplota, data$vlhkostVzduchu, col = "blue", xlim = c(1,30), ylim = c(1,100), xlab = "Teplota (°C)", ylab = "Vlhkosť vzduchu (%)")
dev.off()
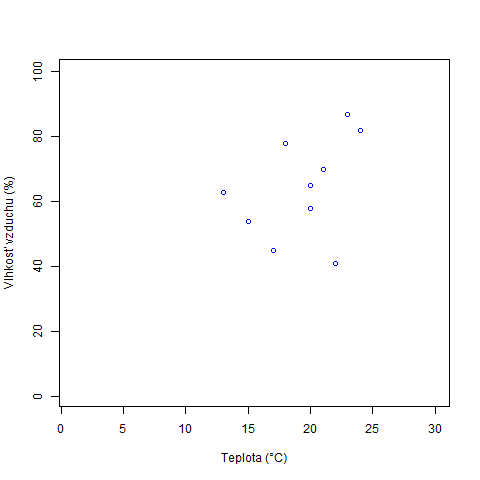
Vytvorený graf vizualizuje vzťah medzi dátami reprezentujúce teplotu a vlhkosťou vzduchu. Zvyšok kódu by už mal byť jasný.
Typické využitie bodového grafu je pri lineárnej regresii. Tá skúma, ako jedná premenná ovplyvňuje druhú a hľadá medzi nimi závislosť. Skúmanie závislosti medzi dvojicou dát robíme cez výpočet rovnice regresnej priamky, ktorú načrtneme do bodového grafu. Rovnica regresnej priamky je v tvare y = ax + b, kde y je závislá premenná, x nezávislá a neznáme regresné koeficienty a a b sa dopočítajú metódou najmenších štvorcov. Toľko na úvod k lineárnej regresii a poďme pridať regresnú priamku do bodového grafu.
data <- read.csv("tabulka.csv",sep=';')
png(file = "scatter_plot.png")
plot(data$teplota, data$vlhkostVzduchu, col = "blue", xlim = c(1,30), ylim = c(1,100), xlab = "Teplota (°C)", ylab = "Vlhkosť vzduchu (%)", abline(lm(data$vlhkostVzduchu~data$teplota)))
dev.off()
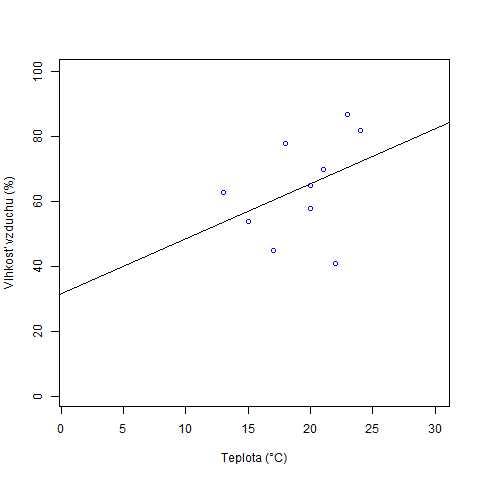
Do funkcie plot() sme pridali funkciu abline(), ktorá pridá do grafu rovnú čiaru. Čiara ako regresná priamka sa skonštruuje podľa pravidiel lineárnej regresie vďaka funkcii lm(). Práve funkcia lm() sa postará o výpočet rovnice regresnej priamky. V našom grafe sú hodnoty vlhkostí vzduchu závisle premenné a hodnoty teploty nezávisle. Čím je bod vzdialenejší od priamky, tým je vzájomný vzťah závislej a nezávislej premennej menší.
Záver
Prostredníctvom praktických príkladov sme si ukázali tvorbu dátových tabuliek, niekoľko funkcii na pohodlnú prácu s nimi a zobrazenie dátových tabuliek do viacerých typov vizuálnych grafov. Ak ste si poctivo naprogramovali všetky príklady, tak by ste mali chápať základnej syntaxe R a mohli tak bezproblémovo pokračovať v štúdiu bohatých možností tohto jazyka.