V posledných rokoch získala technológia strojového učenia značnú pozornosť biomedicíny najmä z dôvodu svojho potenciálu na zlepšenie procesu zisťovania ochorenia. Nový smer, ktorým sa výskum bioinformatiky a strojového učenia budú uberať, určil práve príchod mikropolí DNA a to v posledných dvadsiatich rokoch. Na zhromažďovanie informácií zo vzoriek tkanív a buniek sa využíva práve tento typ dát, ktoré môžu pomôcť diagnostikovať ochorenie alebo rozlíšiť špecifický typ nádoru. Tieto vzorky merajú výkonnosť génu, vďaka čomu dokážeme oddeliť zdravého pacienta od pacienta trpiaceho rakovinou.
Dôležitou časťou strojového učenia je práve výber príznakov (feature selection). Je to proces, v ktorom je počet počiatočných príznakov znížený, a je vybratá podmnožina tých, ktoré uchovávajú dostatok informácií na získanie dobrých alebo ešte lepších výsledkov. Vďaka nemu je to množstvo dát spracovávané algoritmami a nemusíme ho spracovávať samy. Keďže dáta stále pribúdajú, je potrebné ich spracovávať rôznymi metódami výberu príznakov, aby sme zaistili ich čo najpresnejšie vyselektovanie. Táto práca poskytuje prehľad vybraných metód a ich úspešnosť pri analýze dát v dvoch konkrétnych databázach ako aj presnosť predikcie týchto metód.
Výber príznakov
V oblasti strojového učenia existuje veľký počet príznakov, ktorého určenie najmenšej podmnožiny (s najsilnejším účinkom), často znižuje zložitosť modelu a zvyšuje presnosť predikcie. Výber príznakov sa vyznačuje tým, že volí príznaky, ktoré umožňujú jasne definovať problém na rozdiel od tých, ktoré sú nepodstatné alebo nadbytočné. Jeho hlavným cieľom je obmedziť efekt vysokej rozmernosti dátového súboru a nájsť z celej skupiny znakov podmnožinu, ktorá môže efektívne popísať dáta.
Výber príznakov je rozdelený do 3 metód: metódy filtrovania, obalenia, vložené metódy. Mnohé z týchto metód sa zameriavajú predovšetkým na meranie korelácie (alebo podobnosti) medzi dvoma príznakmi. Hlavnou úlohou metódy filtrovania je ohodnotiť rozličné vlastnosti podmnožiny pred zvolením najlepšej z nich. Metódy obalenia zase vyžadujú špecifické učiace algoritmy na ohodnotenie a určenie toho, ktoré vlastnosti budú zvolené. Niektoré konkrétne učiace algoritmy používajú práve vložené metódy, ktoré zahŕňajú rozlišovanie znakov ako súčasť trénovacieho procesu. Metódy výberu príznakov majú významný vplyv na presnosť, stabilitu a interpretovateľnosť znakov. Každá z metód výberu príznakov má svoje silné a slabé stánky. Výkonnosť týchto metód závisí od typu množiny, času, presnosti, nákladov atď. Aj keď je v súčasnosti dostupných stále viac metód výberu príznakov, výskumníci súhlasia s tým, že žiadna z nich nie je ideálna. Jedným z riešení ako zlepšiť stabilitu výberu príznakov je ich skladanie. Táto technika zoberie výsledky viacerých metód výberu príznakov a spojí ich do jednej podmnožiny príznakov.
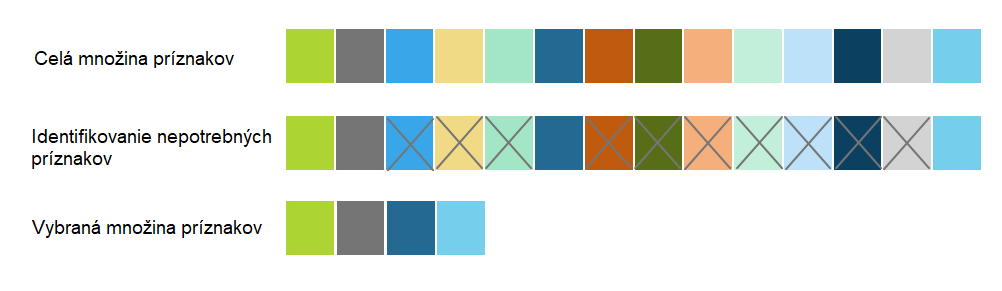
Pri tomto vyhodnocovaní boli použité tri metódy výberu príznakov:
- metóda Fisherovho skóre pre výber príznakov (FS)
- metóda Laplacovho skóre pre výber príznakov (LS)
- metóda Náhodných lesov pre výber príznakov (NL)
a štyri klasifikačné metódy:
- Perceptron (Per)
- Rozhodovacie stromy (RS)
- Klasifikátor náhodných lesov (NL)
- SVM klasifikátor (SVM)
V tejto preáci boli použité 2 dátové sady a pre každú z nich bol počiatočný počet vzoriek iný: pre dátovú sadu Madelon to bolo 500 príznakov z ktorých 5 bolo relevantných a pre dátovú sadu LED bolo 7 dôležitých príznakov zo 100.
Porovnanie výsledkov
-
Index úspešnosti — Succ. index
Index úspešnosti metód je definovaný ako:
Suc. = (Rs/Rt) × 100,
kde Rs je počet dôležitých príznakov, ktoré metóda našla a Rt je počet všetkých dôležitých príznakov. Je nutné poznamenať, že čím vyšší je index úspešnosti, tým je metóda lepšia, a 100% je najvyššia možná hodnota. V prípade, že metóda ako prvé našla všetky dôležité príznaky pred tými nepodstatnými, index úspešnosti bude 100%, vzhľadom na to, že počet nepodstatných príznakov je stále väčší ako počet dôležitých príznakov.
-
Presnosť klasifikácie — Accuracy score
Presnosť klasifikácie bola vypočítaná pomocou funkcie accuracy_score. Táto funkcia vypočíta presnosť buď ako zlomok (predvolené) alebo počet správnych predpovedí. Vo viacvrstvovej klasifikácii funkcia vracia presnosť podsúboru. Ak sa celá množina predpovedaných príznakov pre vzorku presne zhoduje so skutočnou množinou príznakov, presnosť podsúboru je 100; inak je to 0. Presnosť klasifikácie je získaná spriemernením všetkých získaných presností.
Hlavnou časťou tejto práce je zistiť, či existuje nejaká korelácia medzi indexom úspešnosti a presnosťou klasifikácie.
Tieto grafy znázorňujú pre konkrétnu dátovú sadu index úspešnosti jednotlivých metód a presnosť klasifikácie. Týmto spôsobom je ľahké na prvý pohľad vidieť, či najlepšia presnosť zodpovedá najlepšiemu indexu úspešnosti. Y-ová súradnica zobrazuje úspešnosť jednotlivých metód vyjadrenú v %. X-ová súradnica zobrazuje konkrétne použité metódy ako aj index úspešnosti (Succ).
-
dátová sada Madelon
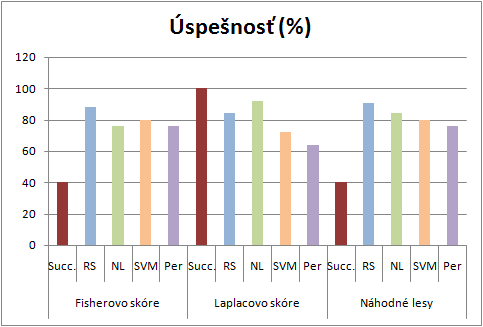
Použitím dátovej sady Madelon index úspešnosti metódy Laplacovho skóre bola najvyššia. Čo sa týka klasifikačných metód, na tejto dátovej sade bola najúspešnejšia metóda Rozhodovacích stromov. Najlepší výsledok indexu úspešnosti získala metóda Laplacovho skóre, ktorá našla všetkých 5 dôležitých príznakov, čo tiež viedlo k najlepšej presnosti klasifikácie pre Náhodné lesy.
-
dátová sada LED
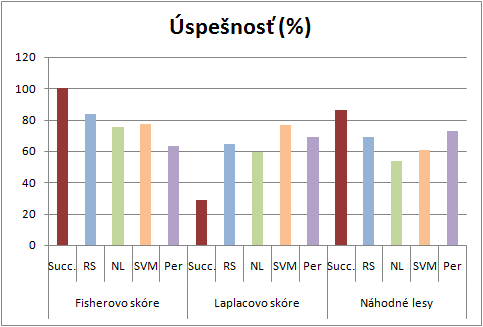
Použitím dátovej sady LED bola metóda Laplacovho skóre najmenej úspešná a našla dôležité príznaky iba s 29% úspešnosťou, najúspešnejšou je metóda Fisherovho skóre pre výber príznakov. Najlepší výsledok indexu úspešnosti mala metóda Fisherovho skóre a to viedlo aj k najlepšej presnosti klasifikácie pre Rozhodovacie stromy.
Záver
Výber príznakov umožňuje efektívne zmenšiť rozmer dátovej sady a to tak, že odstráni nepodstatné a/alebo nepotrebné príznaky. Tieto sady sú zvolené z už existujúcich prvkov, nie sú novovytvorené. Táto práca poskytuje prehľad vybraných metód a ich úspešnosť pri analýze dát v dvoch konkrétnych databázach ako aj presnosť predikcie týchto metód. V tejto práci sme sa zamerali na metódy Fisherovho skóre, Laplacovho skóre a metódu Náhodných lesov pre výber príznakov, ako aj klasifikačné metódy, konkrétne Rozhodovacie stromy, Náhodné lesy, SVM a Perceptron. Použitím dátovej sady Madelon, index úspešnosti metódy Laplacovho skóre pre výber príznakov bol najvyšší, no použitím dátovej sady LED bola táto metóda najmenej úspšená a našla dôležité príznaky iba s 29% úspešnosťou. Čo sa týka klasifikačných metód, na dátovej sade Madelon bola najúspešnejšia metóda Rozhodovacích stromov a takisto aj na dátovej sade LED. Na ovplyvnenie výsledkov môže vplývať veľa faktorov ako je šum, pridanie veľkosti a iné. To môže mať za následok, že aj keď sa zvyšoval index úspešnosti, nie vždy sa zvyšovala aj presnosť predikcie. Takúto výrazne klesajúcu presnosť klasifikácie mala metóda Laplacovho skóre použitím klasifikačnej metódy Náhodných lesov na dátovej sade LED.