Tento článok sa venuje prípadovej štúdii pre rozpoznávanie obrazov s využitím strojového učenia. Čitateľ sa v ňom oboznámi s metodológiou vytvárania modelu v strojovom učení, nadobudne vedomosti z oblasti strojového učenia so zameraním na rozpoznávanie obrazov a následnou implementáciou zvolenej prípadovej štúdie.
Úvod
Metodológia: Proces strojového učenia s učiteľom je z aplikačného hľadiska možné abstrahovať do troch hlavných častí:
- Príprava dátovej sady - Slúži na zber označených dát, ktoré bude možné použiť v procese trénovania a testovania predikčného modelu. Teda cieľom tejto fázy je nazhromaždenie čo najväčšieho počtu dát, pričom dôraz je kladený na získanie reprezentatívnej vzorky dát pre každú skupinu, aby bolo možné vytvoriť čo najlepší a najpresnejší predikčný model. Získané dáta sa rozdelia na trenovacie a testovacie, podľa množstva nazbieraných dát a požiadaviek na model.
- Vytvorenie modelu - Vytvorenia predikčného modelu v sebe zahŕňa prípravu a aplikovanie metód na spracovanie dátovej sady, prípravu a aplikovanie metód pre normalizáciu dát, samotné trénovanie, ktoré v sebe zahŕňa nie len aplikovanie algoritmu strojového učenia, ale aj hľadanie optimálnych parametrov, či uloženie natrénovaného modelu.
- Vyhodnotenie výkonnosti - Hodnotenie výkonnosti a kvality výsledného modelu je samostatná časť, ktorá pracuje s výsledným modelom. V tejto fáze je možné dané riešenie testovať použitím testovacích dát alebo vystaviť tento model testovaniu v produkčnom prostredí.
Pri každom vytváraní modelu strojového učenia je nutné si analyzovať metodológiu budovania riešenia, aby bol model podľa požiadaviek diverzifikovaný na menšie moduly. Čo prináša výhodu pri vzniknutí nových problémov alebo požiadaviek na model, ale aj pri samotnom vývoji.
Problematika rozpoznávania obrazov: Klasifikácia obrázkov v strojom učení znamená zaradiť obrázok do príslušnej triedy podľa toho čo je na obrázku zobrazené a na čo je špecifický model natrénovaný. Triedy sú vždy z vopred definovanej množiny. Pri klasifikácii obrázkov sa používa dátová sada obrázkov, z ktorej sa model učí vzory. Každý dátový bod tejto dátovej sade predstavuje jeden obrázok.
Klasifikácia obrázkov rieši viaceré problémy, ktoré je možné menovite definovať takto:
- Variácie pohľadu – Objekt na obrázku je zobrazený v rôznych uhloch – ne- záleží na tom z akého uhla je objekt fotení stále je to ten istý objekt.
- Zmena veľkosti – Rovnaký objekt je na obrázku zobrazený v rôznej veľkosti – objekt môže vyzerať odlišne keď je fotení z blízka oproti fotenému z diaľky.
- Deformácie – Pozorovaný objekt je deformovaný ale predstavuje stále ten istý objekt.
- Oklúzia - Pozorovaný objekt je sčasti skrytý – objekt je viac viditeľný na jednom obrázku ako na druhom.
- Osvetlenie – Pozorovaný objekt je snímaný v šere, za denného svetlaa lebo v noci – obrysy tohto objektu sú v slabšom svetle horšie rozoznateľné.
- Variabilita v rámci triedy – Jedna trieda definuje širokú škálu rôzne formovaných objektov – dve úplne odlišné objekt patria do rovnakej triedy.
- Rušivé pozadie – Obrázok, na ktorom je zobrazený pozorovaný objekt obsahuje príliš veľa vzorov - nie je jednoduché vybrať správne vzory pre hľadaný objekt.

Problémy klasifikácie obrázkov
Počas vytvárania návrh je potrebné tieto aspekty zahrnúť do analýzy, aby bolo možné zvoliť vhodnú metódu strojového učenia ale taktiež, podľa toho ktorý z týchto aspektov je najviac príznačný pre daný problém, je potrebné upraviť pomer dát v dátovej sade. Keďže nie je možné stále zozbierať dostatočný počet obrázkov, je možné použiť metódy na úpravu obrázkov a tak navýšiť ich počet a zároveň sa vysporiadať s niektorými problémami. Napríklad faktor variácii je možné vyriešiť náhodným otočením obrázkov v rôznych uhloch.
Konvolučné neurónové siete (CNN)
Bežné algoritmy strojového učenia ako napríklad SVM, logistická regresia, metóda rozhodovacích stromov, majú s riešeniami zložitých problémov typu rozpoznávanie obrazov značný problém a vyžadujú si špecifickú extrakciu vlastnosti čo je náročný proces, ktorý nemusí vždy priniesť požadované výsledky. Keď sa pozrieme na existujúce riešenia v súťaži ImageNet 2014 bola použitá metóda hlbokých neurónových sieti. Konkrétne typ konvolučnej siete, ktorá dokázala predikovať výsledky s vyššou presnosťou ako ostatné, vyššie spomenuté metódy strojového učenia. Od roku 2014 všetci víťazi tejto súťaže používali konvolučnú neurónovú sieť, a teda, sa tento fakt dá pokladať za dobrý predpoklad na riešenie rozpoznávania obrazov v strojovom učení.
Konvolučná neurónová sieť je podobná bežným dopredným neurónovým sieťam. Skladá sa z neurónov, kde každý neurón ma učiace sa parametre váhy a odchýlky. Každý neurón prijíma vstupné dáta a výstupom je jedna hodnota. Oproti normálne neurónovej sieti konvolučná neurónová sieť ma neuróny usporiadané v troch dimenziách: šírka, výška a hĺbka, pričom hĺbka reprezentuje parametre jedného pixelu, a teda, formát farieb v RGB. CNN majú veľkú výhodu taktiež v tom, že umožňujú prepojenie malej oblasti neurónov s neurónom z ďalšej vrstvy. Taktiež veľká výhoda CNN je, že určité váhy dokážu byť zdieľané, teda napríklad všetky neuróny v konvolučnej vrstve v danej oblasti a hĺbke majú zdieľané váhy.
Konvolučná vrstva: Konvolučná vrstva je základná vrstva v CNN, ktorá vykonáva väčšinu výpočtov. Pozostáva zo sady filtrov so schopnosťou učiť sa. Každý filter je priestorovo (šírkou a výšou) malý ale úplný do hĺbky. Napríklad filter môže byť veľkosti 5x5x3, t.j. 5 pixel šírka, 5 pixel výška a 3 do hĺbky pretože obrázok má 3 kanály farieb. Počas fázy prechádzania alebo inak povedané počas konvolučnej fázy tento filter prechádza celý vstupný obsah bod po bode a aplikuje na neho filter. Po prechode celého vstupného obsahu dostaneme dvoj dimenzionálnu aktivačnú mapu. Následne sa CNN naučí, že ak uvidí známe hrany v správnej orientácii na prvej vrstve alebo zložitejšie tvary na ďalších vrstvách až po obrazce a vzory na posledných vrstvách tak tieto filtre aktivuje. Následne dostaneme súbor filtrov na každej konvolučnej vrstve, ktoré produkujú samostatné dvoj rozmerné aktivačné mapy. Takto sa konvolučná sieť postupne učí od najvšeobecnejších tvarov na prvých konvolučných vrstvách až po tie najzložitejšie na posledných konvolučných vrstvách.
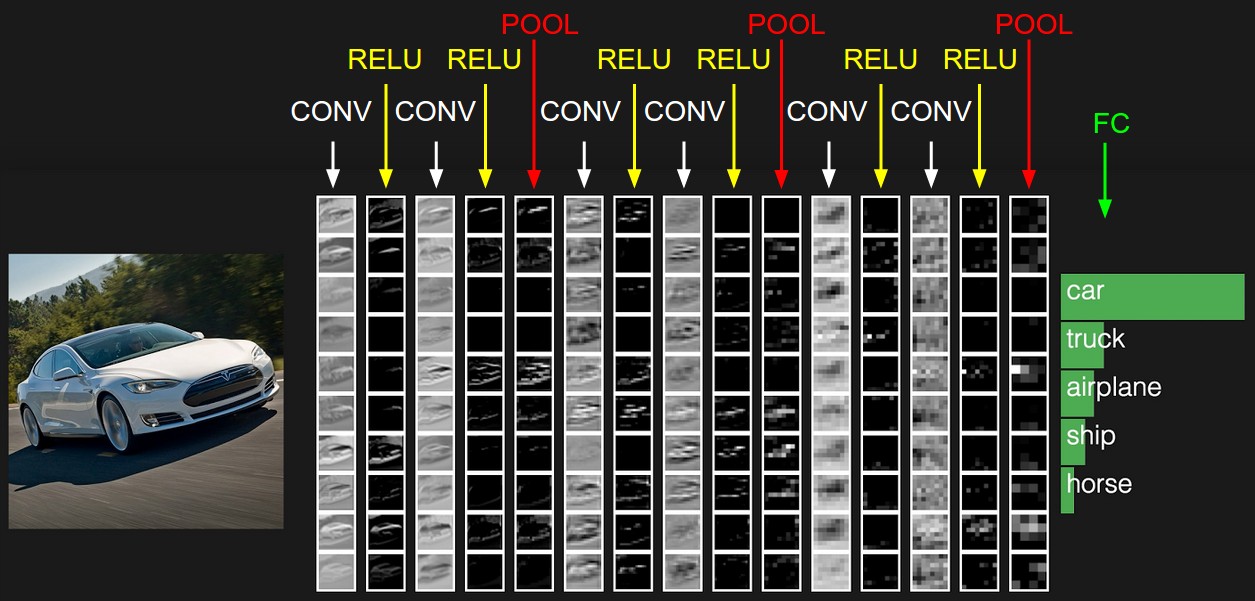
Možnosti učenia CNN: V praktických problémoch nie je veľmi časté trénovať CNN od začiatku s náhodne inicializovanými počiatočnými váhami a odchýlkami. Väčšinou sa natrénuje CNN na veľkej dátovej sade a potom sa táto CNN použije ako inicializácia pre iný problém. Takýto prístup je označovaný ako prenesené učenie a radí sa do týchto dvoch základných tried:
- CNN, ako extraktor príznakov: Je prístup kedy sa použije už natrénovaný model a výstup z niektorej vrstvy použijeme ako vektor príznakov. Pri CNN najčastejšie použijeme výstup z niektorej z predposledných vrstiev a následne tento výstup natrénujeme na nejakom inom algoritme strojového učenia, ako napríklad SVM alebo metóda rozhodovacích stromov.
- Dolaďovanie: Pri tomto prístupe nie len že zoberieme časť už natrénovanej siete, ale taktiež pokračujeme v trénovaní siete a tak odlaďujeme jej váhy na novej dátovej sade. Je možné niektoré vrstvy siete úplne zamraziť a odlaďovať už len niektoré vyššie vrstvy. Tento prístup je vhodný aj z hľadiska predpokladu, že začiatočné vrstvy sa naučili nejaké všeobecné príznaky, ktoré sú prospešné pre viacero problémoch ale vyššie vrstvy sa stávajú postupne špecifickejšie pre detaily tried, na ktorých boli učené. Natrénovanie takej siete je oveľa rýchlejšie ako pri sieti s náhodne inicializovanými počiatočnými váhami.
Definovanie problému
Dátová sada, ktorá bude použitá v tejto prípadovej štúdii je prebraná z najznámejšej stránky so súťažami pre strojové učenie Kaggle.com. Konkrétne budeme používať dátovu sadu zo súťaže s názvom Dogs vs Cats. Cieľom tejto súťaže je dokázať úspešne klasifikovať psa alebo mačku z obrázka. Vstupom pre model strojového učenia bude pred spracovaný obrázok a výstupom bude predikčná hodnota, pre ktorú sa definuje prahový bod pre testovacie účeli výsledného modelu.

Tento model bude používať dátovú sadu Assira, ktorá je vytvorená spoločnosťou Microsoft Research. Táto dátová sada obsahuje 25000 trénovacích obrázkov z čoho na 12500 obrázkoch je zobrazený pes a 12500 obrázkoch je zobrazená mačka. Priemerná veľkosť obrázka je 350x500px.
Návrh implementácie
Návrh implementácie sa opiera o metodologický postup a snaží sa o abstrakciu jednotlivých častí, aby boli ďalej ľahko rozšíriteľné. Podľa metodológie strojového učenia je potrebné implementovať tri časti: pred spracovanie dát, trénovanie a testovanie. Pričom proces trénovania sa bude vykonávať iteratívne a bude pozostávať z viacerých krokov. Na základe týchto predpokladov sú definované požiadavky na systém:
- Operácie nad obrázkami sú časovo náročné, preto bude každá z týchto časti vyvíjaná, vykonávaná a spustiteľná nezávislé od ostatných. Pre jednotlivé časti to znamená, že po spustený bude vykonaná iba jedna akcia, ktorá pripraví všetko potrebné pre nasledujúcu akciu. Z toho vyplýva, že pri prvom použití bude potrebné používať modul podľa metodológie.
- Proces pred spracovania pripraví dáta pre akciu trénovania podľa požiadaviek trénovania.
- Proces trénovania bude schopný načítať si dáta z vopred dohodnutej štruktúry pred spracovaných dát. Proces trénovania modelu bude možné vykonávať iteratívne, teda bude spustiteľný viac krát s použitím rôznych parametrov, na základe čoho sa potom vyberie ten správny. Preto je potrebné implementovať systém, ktorý bude celú aktivitu zaznamenávať. Keďže dopredu nie je možné určiť koľko iterácii bude dostačujúcich je potrebné zvoliť systém zaznamenávania, v ktorom sa bude možné ľahko orientovať.
- Vo fáze testovania bude mať testovací modul pripravený model vo vopred dohodnutej štruktúre.
- V každej fáze, podľa metodológie, je vhodné pripraviť prostredie, ktoré bude podporovať vizualizáciu riešenia, aby bola daná fáza ľahšie interpretovateľná.
- Efektívny a kontrolovaný proces trénovanie.
Implementácia trénovania
Zaznamenávanie trénovacieho procesu: Trénovanie je dlhodobý proces, počas ktorého sa testujú rôzne prístupy, optimálne parametre, a pod. Preto je nevyhnutné implementovať systém, ktorý by celý proces zaznamenával a bolo možné sa spätne vrátiť k predošlým výsledkom testov. K tomuto predpokladu boli v návrhu definované základne body, ktoré bude implementácia spĺňať. Aby mohol byť výstup prehľadný budeme implementovať detailný zápis výstupu do tabuľky, s príslušnými parametrami pre algoritmus strojového učenia a zobrazenie trénovacieho progresu v grafe.
Samotná knižnica Keras ponúka veľmi užitočné možnosti, ako zaznamenávať výstup z trénovania. Do Keras modelu je možné vložiť spätné volanie (callback) funkcie, ktorá sa vykonaná po každej epoche. Pre účeli tohto riešenia sú zaujímavé triedy BaseLogger a CSVLogger. Každá z týchto tried má funkciu on_epoch_end, ktorá sa zavolá po vykonaní každej epochy, taktiež v sebe obsahujú objekt History, ktorá je nositeľom týchto informácii:
- train_acc - správnosť nad trénovacími dátami,
- val_acc - správnosť nad validačnými dátami,
- train_loss - strata nad trénovacími dátami,
- val_loss - strata nad validačnými dátami.
Pre toto riešení je vhodnejšie používať triedu CSVLogger, ktorá priebežne ukladá proces trénovania do .csv súboru, takže všetky údaje sú okamžite k dispozícií aj keby proces trénovania neočakávane skončil.
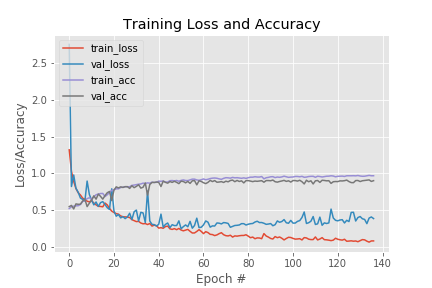
Objekt History je taktiež návratová hodnota po natrénovaní modelu. Je možné ho použiť na vykreslenie dát do grafu. Kód pre vykreslenie grafu z hodnôt jednotlivých epoch je prebratý z oficiálnej dokumentácie knižnice Keras. Pri jeho implementácii sa používa knižnica matplot. Z tohto grafu je potom možné veľmi rýchlo vyčítať priebeh trénovania modelu. Ako môžeme vidieť na obrázku, že po 60. epoche došlo k pretrénovaniu modelu.
Každý algoritmus strojového učenia má iné optimálne parametre trénovania, ktoré zvyšujú výkonnosť a znižujú trvanie trénovania, preto je nevyhnutné implementovať proces hľadania týchto parametrov. Pre efektívne hľadania optimálnych parametrov bola zvolená metodológia náhodného vyhľadania. Na vyhľadávanie optimálnych parametrov pre Keras existuje viacero knižníc, ako napríklad: Hyperas, Talos. Tieto knižnice tretích strán zaobaľujú trénovaciu funkciu a vkladajú do nej parametre z vopred definovaného rozsahu. Nie sú však priamou integráciou Keras knižnice, z čoho môžu vznikať problémy pri ich integrácii do projektu a ďalšom vývoji, taktiež je všeobecne známe, že čím má projekt viac závislostí tým horšie je dlhodobo udržiavateľný. Ako príklad by som uviedol, že knižnice nepodporujú metódu fit_generator z knižnice Keras, s ktorou sa stretneme neskôr. Samotná implementácia vyhľadávania optimálnych parametrov metodológiou náhodného vyhľadávania je v podstate použitie všetkých kombinácii jednotlivých parametrov z množiny vopred definovaných parametrov. Na základe tohto tvrdenia bol implementovaný vlastný modul s názvom my_random_search. Ako vstup si vyžaduje funkciu, ktorú bude volať pre zadané parametre; všetky vyžadované parametre obsiahnuté v dict objekte, ktorý obsahuje jednotlive parametre v poliach alebo tripletoch, kde prvý parameter je začiatočná hodnota, druhý konečná hodnota a tretí počet rozdelení. Z vložených parametrov sa vytvoria permutácie a následne sa zavolá vstupná funkcia s jedným záznamom z permutačnej tabuľky.
# Definovanie objektu pre hľadanie optimálnych parametrov
hyper_parameters = {’lr’: [0.2, 0.1, 0.01, 0.005],
’decay’: (0.2, 0.005, 5),
’loss’: ["binary_crossentropy"],
’loss_limit’: [3.0],
’optimizer’: [’adam’, ’sgd’],
’epochs’: [20, 40, 60, 80, 100],
’batch_size’: [12, 24, 48, 64]}
V ďalšej implementácii bola funkcia my_random_search rozšírená o integráciu zaznamenávania. Po každom zavolaní funkcie trénovania je návratová hodnota objekt History. Objekt obsahuje výsledné hodnoty trénovania (správnosť a strata), ktoré zapíše do .csv súboru spolu so vstupnými hodnotami trénovacej funkcie. Objekt History sa následne odošle do funkcie pre vykreslenie grafu. Takto dostaneme grafický výstup z trénovania ale aj detailný priebeh trénovania pre každú sadu parametrov.
Ďalší problém, ktorý bol riešení počas implementácie optimálnych parametrov bol prípad kedy trénovanie dlhodobo vykazovalo veľkú stratu nad validačnými dátami, vtedy je zjavné, že parametre sú nesprávne nastavené a proces trénovania môže byť explicitne prerušený. V implementácii bola použitá trieda EarlyStopping z knižnice Keras. Táto trieda dovoľuje definovanie podmienok na zastavenie trénovania. Konkrétne počas trénovania modelu sa po každom vykonaní epochy kontroluje val_loss hodnota, na základe ktorej sa rozhodne či má zmysel pokračovať v trénovaní.
Pred spracovanie dát: CNN oproti obyčajnej neurónovej sieti predpokladá na vstupe troj rozmerné pole s pevnou šírkou, výškou a hĺbkou pre každý dátový bod. V reálnom svete sú však obrázky rôznych rozmerov s rôznym priestorovým rozmiestnením, kvôli čomu si vstupné obrázky vyžadujú spracovanie do jednotných rozmerov. Pri spracovaní je osvedčené zachovať pomer strán obrázka, aby nedochádzalo k deformácii tvarov a zvyšný priestor vyplniť podľa okrajov obrázka. Počas implementácie bude využitá hlavne knižnicu openCV, ktorá poskytuje široké spektrum algoritmov v oblasti strojového videnia. Implementácia zmeny veľkosti obrázka do jednotných rozmerov.
# Zmenšenie obrázka na požadovanú veľkosť
def image_resize(image, size=32):
dims = net_dims(image, size)
# zmenší obrázok podľa šírky alebo podľa výšky
resize = openCV.resize(image, dims, interpolation=openCV.INTER_AREA)
# výpočet výplne
padW = int((size - resize.shape[1]) / 2.0)
padH = int((size - resize.shape[0]) / 2.0)
# pridanie výplne do okrajov obrázka ak je to potrebné
image = openCV.copyMakeBorder(resize, padH, padH, padW,
padW, openCV.BORDER_REPLICATE)
# je potrebné obrázok ešte upraviť kvôli zlému zaokrúhleniu => +/-1 pixel
return openCV.resize(image, (size, size))
Funkcia očakáva na vstupe obrázok načítaný použitím metódy openCV.imread a veľkosť výstupných rozmerov. Podľa pomeru strán obrázka si funkcia vypočíta nové rozmery. Teda ak je väčšia šírka je potrebné nastaviť šírku na požadovanú veľkosť a následné si vypočítať výšku tak, aby bol zachovaný pomer strán. Ak obrázok nebude mať štvorcové rozmery, tak po aplikovaní zmeny veľkosti je nutné menší z rozmerov doplniť o zvyšok požadovanej veľkosti rovnomerne z oboch strán. Kvôli zaokrúhleniu na celé čísla môže byť výpočet nekorektný a teda obrázok bude mať o jeden pixel viac alebo menej, čo spôsobí zlyhanie trénovania konvolučnej neurónovej siete. Preto sa aplikuje funkcia na zmenu veľkosti ešte raz.

Neurónová sieť vyžaduje na vstupe normalizované dáta, aby dokázala pracovať optimálne. Pre CNN to znamená že tretí rozmer, ktorý predstavuje RGB hodnoty a teda je na škále od 0 do 255 si vyžaduje škálovanie do rozsahu od 0 po 1. Škálovanie aplikujeme použitím delenia variáciou hodnôt nasledovne:
# konvertovanie obrázka do poľa požadovaného pre knižnicu Keras
image = K.img_to_array(new_image)
# normalizácia poľa
new_image = numpy.array(image, dtype="float") / 255.0
Knižnica Keras využíva na pozadí funkcie iných knižníc, ako napríklad Tensorflow alebo Theano. Ak sa pozrieme do dokumentácie pre tieto knižnice zistíme, že Tensorflow si vyžaduje na vstupe obrázok v tvare (šírka, výška, hĺbka) zatiaľčo Theano v tvare (hĺbka, šírka, výška). Preto je dobrým zvykom používať funkciu img_to_array, ktorá zabezpečuje správny tvar vstupu pre CNN.
V ďalšom procese sa budú aplikovať definované metódy pred spracovania obrázka postupne na trénovaciu a testovaciu sadu dát. Obrázky budú načítané zo súborovej sústavy operačného systému. Na prácu so súborovou sústavou bude použitá knižnica glob, ktorej je potrebné definovať zdrojový adresár a súbory, ktoré má prehľadávať použitím regex syntaxe. Pre účeli tohto riešenia sa budú vybrané všetky súbory s príponou .jpg z datasetového adresára. Po aplikovaní tejto knižnice dostaneme všetky adresy z definovanej štruktúry. Problém je v tom, že tieto adresy nie sú usporiadané tak, ako by sme ich mohli vidieť v nejakom systémovom prehľadávači súborovej sústavy. Čo znamená, že po rozdelení na trénovacie a validačné dáta by mohli byť obrázky psov a mačiek v nepomere. Taktiež pri trénovaní siete po opätovnom spustený pred spracovania by trénovacia a validačná sada obsahovala iné dáta čo by viedlo k skresľovaniu výsledkov. Tento problém je možné riešiť dvoma spôsobmi rozdeliť dáta do viacerých adresárov podľa účelu a potreby alebo aplikovať nejaký postup, ktorý nám vráti adresy stále v rovnakom usporiadaní. Výhodou prvého je ľahšia implementovateľnosť, nižšia výpočtová výkonnosť, nevýhodou je však horšia modifikovateľnosť a prakticky žiadna rozšíriteľnosť. Preto bol zvolený druhý postup a teda po načítaní všetkých adries sa obrázky ešte usporiadajú podľa čísla označenia.
# načítanie adries obrázkov
addrs = glob.glob(source_dir)
# usporiadanie obrázkov podľa čísel
addrs.sort(key=lambda addr: int(addr.split(os.path.sep)\[-1\][4:-4]))
Výhodou tohto prístupu je hlavne možnosť rozšírenia o krížovú validáciu.
Po načítaní z adries vyberieme označenia cat a dog. Keďže konvolučná neurónová sieť nevie pracovať s textovými označeniami použijeme LabelEncoder z knižnice sklearn a prevedieme textové hodnoty na číselné. Keď už je pole s adresami a príslušnými označeniami načítané je možné postupne prechádzať adresy, aplikovať metódy pred spracovania a spolu s príslušnými označeniami ich uložiť do vopred dohodnutého formátu súboru.
Pri práci s obrázkami nastáva problém s nedostatkom hardvérových zdrojov, keďže obrázky sú pamäťovo náročné, tak nie je možné pracovať so všetkými naraz. Namiesto toho je potrebný format súboru, ktorý dovoľuje, tzv. lenivé načítavanie a musí podporovať prácu s komplexnými dátami. V oblasti strojového učenia sa preto často využíva format súboru hdf5, ktorý budeme využívať počas implementácie riešenia.
Implementácia CNN
Proces vytvárania konvolučnej neurónovej siete je náročný, pričom si vyžaduje skúsenosti a teoretické základy z tejto oblasti. Konvolučné neurónové siete obsahujú veľké množstvo premenných, ktoré je možné meniť pričom aj nepatrná zmena môže výrazne ovplyvniť nadobudnuté výsledky. Preto je v procese učenia nevyhnutné postupovať systematicky v iteráciách a spätne si analyzovať výsledky, či daná zmena priniesla pozitívny alebo negatívny dopad.
Keďže cieľom tejto prípadovej štúdie nie je natrénovaná sieť ale proces trénovania, tak budú obrázky spracované do veľkosti 96 × 96 pixelov. Tým zabezpečí, že riešenie bude jednoduchšie aplikovateľné pre širšiu škálu čitateľov, čo bude viesť k rýchlejšiemu pochopeniu a naučeniu sa základných princípov strojového učenia.
V rámci tejto práce bola implementovaná CNN, ktorá stojí na princípoch VGG-Net. Princípy boli aplikované pre obrázok definovanej veľkosti.
def VGG_NET(image_size)
# inicializácia modelu
model = Sequential()
# rozpoznanie vstupného formátu pre model
inputShape = (image_size[0], image_size[1], 3)
if K.image_data_format() == ’channels_first’:
inputShape = (3, image_size[0], image_size[1])
# vstupná vrstva > CONV(32) > ReLU > BN > MAX_POOL(3x3) > DP(0.25)
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape, activation=’relu’))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
# (CONV(64) > ReLU > BN) * 2 > MAX_POOL(2x2) > DP(0.25)
model.add(Conv2D(64, (3, 3), padding="same", activation=’relu’))
model.add(BatchNormalization())
model.add(Conv2D(64, (3, 3), padding="same", activation=’relu’))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# (CONV(128) > ReLU > BN) * 2 > MAX_POOL(2x2) > DP(0.25)
model.add(Conv2D(128, (3, 3), padding="same", activation=’relu’))
model.add(BatchNormalization())
model.add(Conv2D(128, (3, 3), padding="same", activation=’relu’))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# FC(1024) > BN > DP(0.5)
model.add(Flatten())
model.add(Dense(1024, activation=’relu’))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# FC(počet tried) > SOFTMAX
model.add(Dense(2))
model.add(Activation("softmax"))
return model
Model postupne zväčšuje počet použitých filtrov na jednotlivých konvolučných vrstvách (CONV), pričom zachováva veľkosť obrázka. Po každej CONV sa aplikuje ReLU aktivačná funkcia. Na prvej úrovni nasleduje deštrukcia obrázka za pomoci max POOL vrstvi o veľkosti 3×3. Ďalšie úrovne obsahujú dve konvolučné vrstvy s navýšením počtom filtrov a deštrukčnou vrstvou o veľkosti 2×2. Jednotlivé úrovne sa aplikujú až pokým nie je veľkosť obrázka zredukovaná na veľkosť 8×8 pixelov. Výstup z poslednej konvolučnej vrstvy sa následne vyhladí, do jednorozmerného poľa, za pomoci triedy Flatten, kde sa pred poslednou vrstvou aplikuje plne prepojená vrstva s 1024 neurónmi. Posledná vrstva aplikuje množstvo neurónov o počte výstupných tried, na ktoré sa aplikuje SOFTMAX aktivačná funkcia, ktorej výstup je označenie jednej z dvoch tried.
Pre urýchlenie trénovania bol model taktiež obohatený o vrstvy normalizácie dávky. Po každej úrovne siete bola aplikovaná vrstva prerušenia, ktorá zabezpečila, že model mohol byť trénovaný použitím viacerých epoch bez toho, aby sa pretrénoval.
Pre implementovanú sieť bola aplikovaná metóda hľadania optimálnych parametrov. Počiatočné parametre boli inšpirované parametrami použitými v práci o VGGNet. Ďalej boli tieto parametre modifikované a rozširované v iteráciách pokým sa nenašli najoptimálnejšie. Pri dostačujúcom počte výsledkov v danej iterácii boli výsledky analyzované a bol zhodnotený nasledujúci priebeh hľadania, čím sa zúžil okruh hľadaných optimálnych parametrov. Priebeh posledného trénovania je možné vidieť na nasledujúcom obrázku.
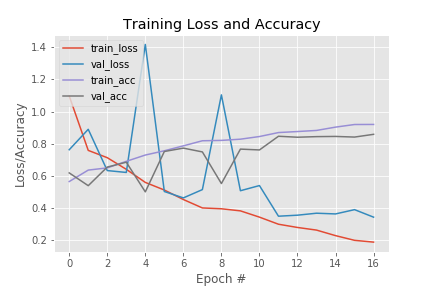
V priloženom grafe je zaujímavé vidieť vychýlenia vo 4. a 8. epoche. Tieto odchýlky sú spôsobené optimalizátorom Adam, ktorý výrazne zrýchlil trénovanie, znížil potrebný počet epoch trénovania a tým zabezpečil, že nedošlo k pretrénovaniu siete. Pri použití optimalizátora SGD vyzeral graf trénovania viac plynulý, teda sieť bola trénovaná pomalšie ale naopak dochádzalo k pretrénovaniu siete. Tento problém sa pri testovaní nepodarilo odstrániť a tak sa ukázal Adam, ako vhodnejší optimalizátor, čo je potvrdené aj vo viacerých literatúrach. Taktiež sa môže zdať, že sieť by mohla byť ešte ďalej trénovaná, pretože validačná správnosť ma v 16. ešte stúpajúcu tendenciu. Toto tvrdenie sa však nepotvrdilo a sieť dosahovala po viacerých epochách horšie výsledky na testovacích dátach. Natrénovaná sieť bola schopná dosiahnuť 85,83% správnosť na validačných dátach. Pričom na trénovacích dátach sieť dosahuje správnosť až 91,96%. Táto odchýlka pri prvom dojme ukazuje na pre trénovanú sieť ale v priebehu testovania sa ukázala táto sieť ako najoptimálnejšia. Je zrejme, že neboli vhodne zvolené trénovacie a testovacie dáta a pre presnejšie výsledky je nevyhnutné použiť krížovú validáciu, zmeniť pomer trénovacej a testovacej sady a v neposlednom rade v procese pred spracovania navýšiť dátovú sadu.
Vyhodnotenie
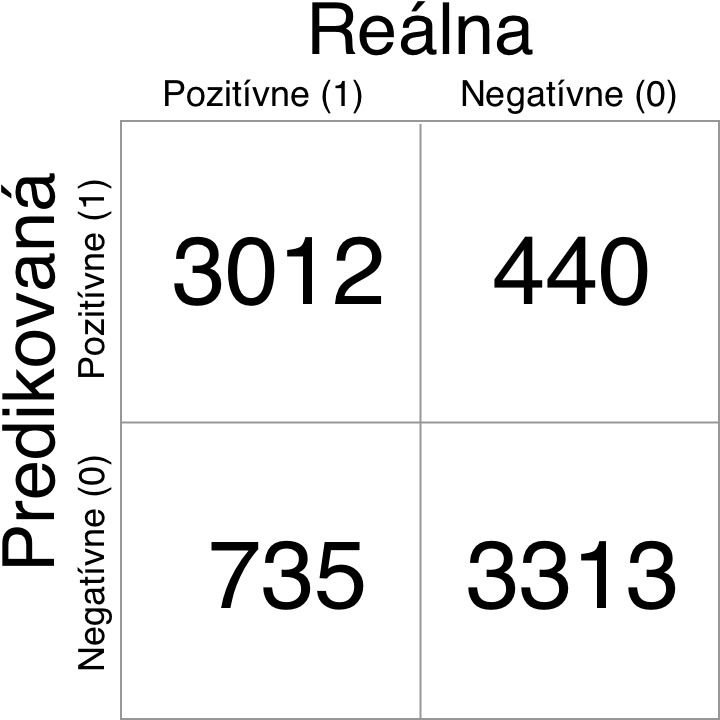
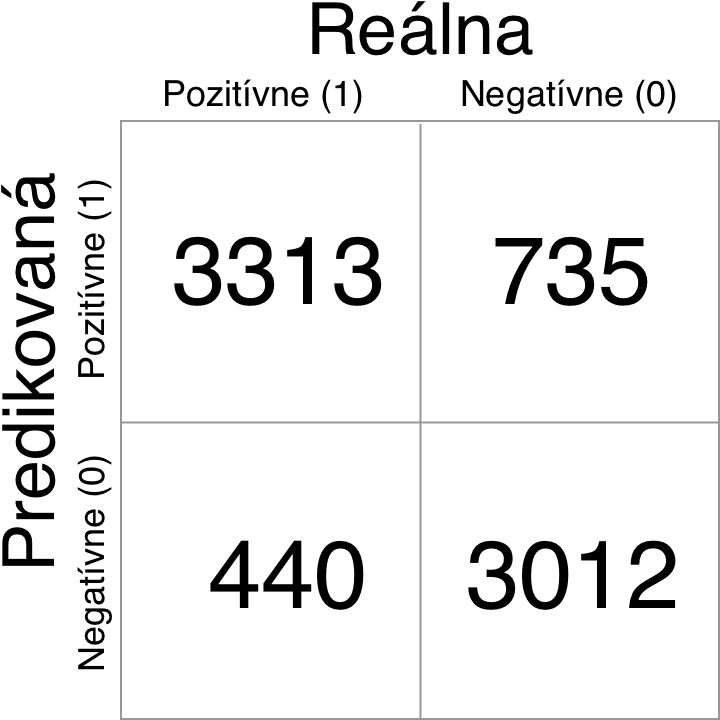
Finálne natrénovaná sieť dosiahla najlepšiu správnosť 84,33% so stratov 0.3391. Čo považujem za dobrý výsledok vzhľadom na to, že boli použité obrázky o veľkosti 96×96 pixelov a začiatočná inicializácia siete bola náhodná. Z konfúznej matice predikcii a reálnych hodnôt je viditeľné, že lepšie výsledky sú dosiahnuté pre kategóriu psov, čo môže byť spôsobené tým, že psy mali lepšiu reprezentatívnu vzorku obrázkov v trénovacích dátach, psy sú taktiež zobrazované prevažne vo svetlejšom prostredí a teda sú ich vlastnosti pre CNN ľahšie rozoznateľné. Bližšiu analýzu dosiahnutých výsledkov by bolo možné previesť ak by počas trénovania bola použitá technika krížovej validácie, ktorá dokáže pomôcť zistiť, ktorá vzorka dát je najvhodnejšia na trénovanie. Taktiež by sa ukázala najmenej vhodná vzorka dát, čo by mohlo viesť k následným úpravám dátovej sady alebo doplneniu techník pred spracovania dát.
Ďalšia časť vyhodnotenia natrénovanej siete je zameraná na predikčné hodnoty konkrétnych obrázkov, čo slúži na lepšie pochopenie siete ale aj na spozorovanie nedostatkov siete. Z obrázkov je možné vyčítať, že natrénovaná sieť najlepšie pracuje, keď je na obrázku dobre viditeľná tvár mačky zobrazená spredu.

Pri pohľade na obrázky psov môžeme dedukovať podobné rozoznávacie črty a teda dobre viditeľná tvár je najdôležitejšia časť pre natrénovanú sieť.

Obrázky najhorších predikcii sa na prvý pohľad nejavia ako ťažko rozoznateľné. Keďže bola inicializovaná s náhodnými hodnotami veľmi ľahko môžu vznikať problémy kedy sa na nejakej vrstve nerozhodne správne.

Z priložených obrázkov je možné dedukovať, že sieť nedokáže jednoznačne identifikovať zvieratá, ktoré sú prevažne tmavé alebo nie su jednoznačné črty tváre. S najväčšou pravdepodobnosťou je to spôsobené tým, že sieť bola náhodne inicializovaná teda sa musela učiť od najzákladnejších vlastností, čo nebolo možné realizovať pre tak malú dátovú sadu. Preto by som ako ďalší postup navrhoval použiť už natrénovanú konvolučnú neurónovú sieť a použil techniku dolaďovania pre túto dátovú sadu. Pri nedostatočných výsledkoch je ešte možné rozšíriť pred spracovanie o techniky orezania, natočenia obrázka v určitom uhle, zrkadlového otočenia, zosvetlenia a stmavnutia obrázka.
Výsledky sú do veľkej miery ovplyvnené zvolenou veľkosťou obrázkov. Teda pre dosiahnutie presnejších predikcii je potrebné použiť väčšie obrázky a príslušne upraviť CNN, čo by viedlo k lepšej selekcii vlastností a následne lepšej predikcii.
Odkaz k zdrojovému kódu prípadovej štúdii: https://git.kpi.fei.tuke.sk/oz592cu/dp-workdir/tree/master/dogs_vs_cats