Knižnice údajových štruktúr a algoritmov slúžia na uľahčenie práce programátorov. Ponúkajú riešenia, napísané odborníkmi, ktoré sú čo najviac optimalizované. Niektoré knižnice sú špecializované na konkrétne údajové štruktúry a prácu s nimi, iné sú všestrannejšie a vhodné na univerzálne použitie. Na to, aby sme vedeli vybrať tie správne knižnice, na použitie v našom projekte, je potrebné poznať ich výhody, obmedzenia a na základe toho sa rozhodnúť. Tento článok poskytuje prehľad o aktuálnych, relevantných knižniciach údajových štruktúr a algoritmov.
Abstraktné údajové štruktúry
Abstraktná údajová štruktúra (ADT) je definovaná, ako matematický model s nejakou množinou operácií, ktoré môžu byť vykonané nad ňou. Zo zadefinovania ADT je jasné, aké operácie sú dostupné nad konkrétnou údajovou štruktúrou a čo majú jednotlivé operácie dosiahnuť, nie je však určené, akým spôsobom to majú robiť. Preto rozdielne implementácie z rôznych knižníc nemusia mať rovnaký výkon a rovnaké požiadavky na pamäť.
V tomto článku sa hlavne zameriavame na nasledujúce údajové štruktúry:
- Zoznam: lineárna kolekcia prvkov, kde záleží na poradí prvkov. Zoznam môže, ale nemusí byť zotriedený.
- Množina: kolekcia prvkov, kde nezáleží na poradí prvkov, k prvkom sa nepristupuje pomocou indexov. V klasickej množine sa každý prvok môže vyskytovať iba raz, ale variant MultiSet dovolí aj duplicitné prvky.
- Prioritný front: kolekcia prvkov, kde každý prvok je asociovaný s nejakou prioritou, ktorá určuje jeho poradie v prioritnom fronte.
- Slovník: asociuje jedinečné kľúče s hodnotou, alebo viacerými hodnotami. ADT slovník a zobrazenie (map) sú si podobné. Variant multimap umožňuje ukladanie viacerých hodnôt s jedným kľúčom.
- Strom: orientovaný acyklický graf, skladá sa z množiny vrcholov. Jeden z vrcholov je koreň stromu, všetky ostatné vrcholy majú jedného predchodcu a môžu, ale nemusia mať potomkov.
- Graf: skladá sa z množiny vrcholov a z množiny hrán. Mnohokrát sa používa na reprezentáciu relácií medzi objektmi. Existuje mnoho rôznych typov grafov, napríklad orientované, neorientované, hranovo ohodnotené, atď.
Algoritmy
Aby sme mohli efektívne pracovať s údajovými štruktúrami, nie stále stačia základné operácie, definované nad nimi. Pomocou algoritmov, špecializovaných na jednu konkrétnu úlohu, vieme manipulovať a pracovať s jednotlivými údajovými štruktúrami. V článku sú knižnice porovnané na základe nasledujúcich algoritmov:
- Triediace algoritmy: slúžia na zoradenie prvkov v nejakej kolekcii, napríklad Merge sort, Heap sort, Quick sort a Radix sort.
- Vyhľadávacie algoritmy: majú za úlohu nájsť konkrétny prvok vo veľkej kolekcii.
- Stromové algoritmy: patria tu hlavne rôzne stratégie označovania stromov (Preorder, Postorder a Inorder).
- Grafové algoritmy: uľahčujú prácu s ADT graf, patria tu algoritmy na systematické prechádzanie grafom (Breadth First Search - BFS, Depth First Search - DFS), alebo hľadanie minimálnej kostry grafu.
Knižnice údajových štruktúr
Knižníc údajových štruktúr a algoritmov pre jazyk Java je dostupných niekoľko. Java Collections Framework poskytuje implementácie pre základné údajové štruktúry a je zahrnutý priamo v Jave. Avšak keď potrebujeme použiť viac špecifické štruktúry, implementácie z Java Collections nemusia byť postačujúce. V tomto článku sa zameriavame na Java Collections Framework (JC), Data Structures Library for Java (JDSL), Java Universal Network/Graph Framework (JUNG), Google Core Libraries for Java (GUAVA), Apache Commons Collections (CC) a JGraphT.
Java Collections Framework
V knižnici Java Collections (JC) nájdeme implementácie pre všetky základné údajové štruktúry, ako zoznam, množina, prioritný front a slovník, chýbajú však zložitejšie štruktúry, ako strom a graf. JC je jediná zo spomenutých knižníc, ktorá obsahuje implementáciu algoritmu binárneho vyhľadávania. Ďalej, poskytuje aj triediace algoritmy, konkrétne TimSort (na triedenie zoznamov a polí objektov) a Quick sort (na triedenie polí primitívnych typov). Z výkonového hľadiska, implementácie údajových štruktúr a algoritmov z knižnice JC dosahovali najlepšie výsledky vo väčšine meraní.
Java Collections je praktická, pre jej použitie nie je potrebné importovať žiadnu inú knižnicu. Je postačujúca, keď nie je potrebné použiť zložitejšie údajové štruktúry. JC je neustále aktualizovaná, implementácie, ktoré poskytuje, využívajú najnovšie technológie ponúkané jazykom Java. Údajové štruktúry z knižnice JC sú použiteľné v mnohých rôznych situáciách, a sú jednoduché na použitie.
Data Structures Library for Java
JDSL je staršia knižnica, posledná verzia (2.1.1) je z roku 2005, ale môžeme v nej nájsť implementáciu každej spomenutej údajovej štruktúry, okrem ATD množina. Poskytuje flexibilnejší prístup k prvkom pomocou rôznych accessorov (Accessor v knižnici JDSL poskytuje prístup k prvkom kolekcií a iných údajových štruktúr, nezávisle od implementácie). Zo spomenutých knižníc, JDSL pokryje najviac údajových štruktúr a algoritmov. Nájdeme tu implementácie binárneho stromu, stromu na všeobecné použitie, grafu, algoritmov prechodu stromom, grafové algoritmy a ešte mnoho ďalších štruktúr, či algoritmov. Tieto implementácie nedosiahli dobré výsledky pri meraní výkonu, čo môže byť spôsobené aj vekom tejto knižnice.
Najväčšia nevýhoda knižnice JDSL je, že od roku 2005 nebola aktualizovaná, čo znamená, že používa technológie, ktoré boli prístupné v tej dobe. Chýba v nej podpora generických typov, čo môže spôsobovať nekompatibilitu typov počas behu programov. Názvy operácií môžu byť tiež mätúce, lebo sa často odlišujú od pomenovaní v ostatných knižniciach. Namiesto knižnice JDSL je výhodnejšie použiť niektorú inú zo spomenutých knižníc.
Java Universal Network/Graph Framework
JUNG je open-source knižnica, ktorá slúži na modelovanie, analýzu a vizualizáciu údajov, reprezentovateľných pomocou grafov. Okrem grafových údajových štruktúr ponúka aj implementácie ADT strom a slovník. Nájdeme tu aj algoritmy na vytváranie podgrafov, výpočet maximálneho toku v sieti, hľadanie najkratšej cesty v grafe a ešte mnoho ďalších algoritmov z teórie grafov. Autori odporúčajú túto knižnicu pre programátorov, ktorí majú záujem o grafy, ale nie sú expertmi v problematike. Je vhodná na vytváranie nástrojov a aplikácií súvisiacich s prieskumom sietí a grafov. V JUNG sú zahrnuté ukážkové triedy, ktoré demonštrujú schopnosti knižnice.
Vizualizácia grafov pomocou JUNG
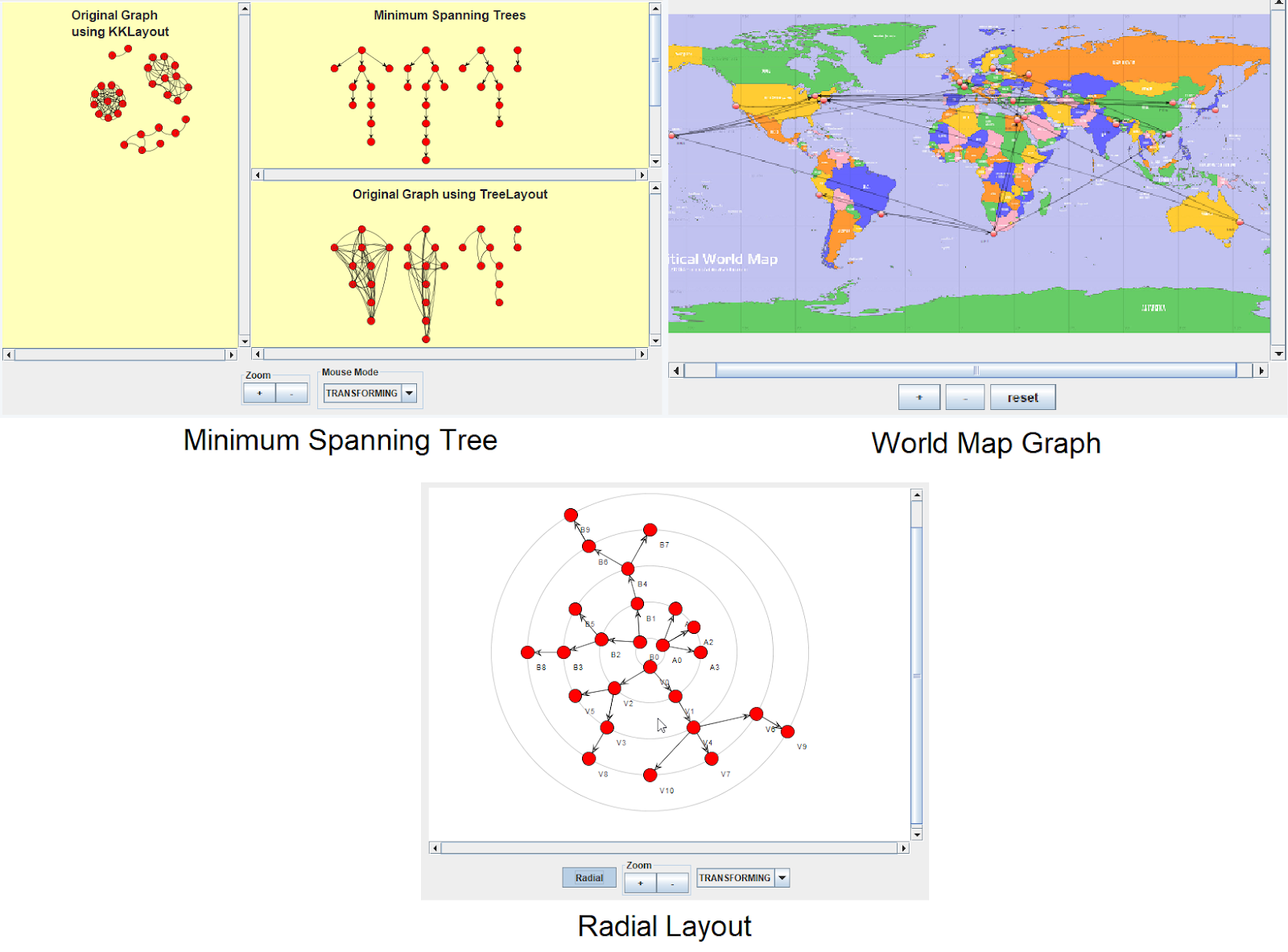
Knižnica JUNG poskytuje silné nástroje na vizualizáciu grafov. Tieto nástroje sú priamo zahrnuté v knižnici v balíčku edu.uci.ics.jung.visualization. Na nasledujúcom obrázku je znázornená vizualizácia grafov pomocou vstavaných nástrojov JUNG:
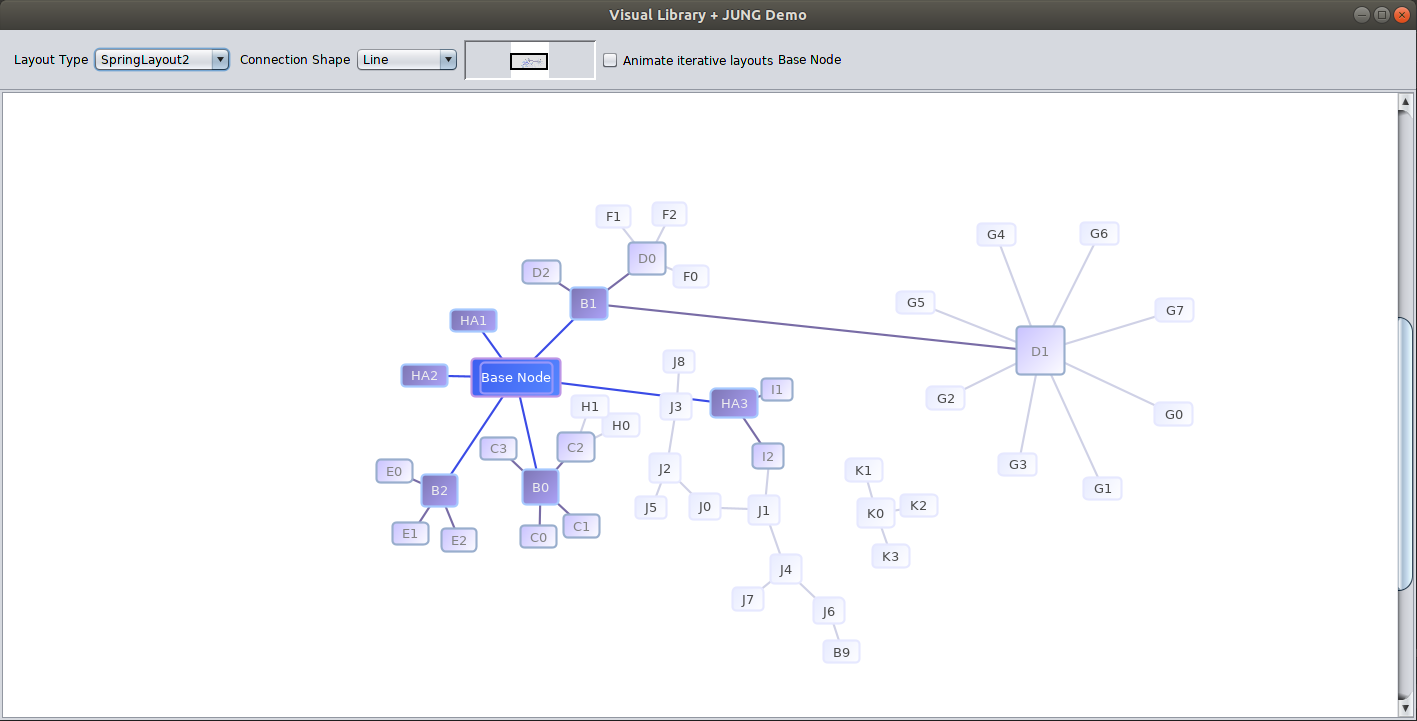
Ďalšia možnosť vizualizácie grafov je použitie knižnice Vl-jung. Vl-jung je kombináciou knižníc JUNG a Visual Library. Visual Library spestrí zobrazenie grafov rôznymi animáciami, režimami zobrazovania, používateľským rozhraním a možnosťou interakcie. Nasledujúci obrázok znázorňuje ukážku použitia knižnice Vl-jung:
Google Core Libraries for Java
Knižnicu GUAVA aktívne vyvíja spoločnosť Google, a používa ju skoro vo všetkých projektoch, písaných v jazyku Java. Môžeme v nej nájsť implementáciu (alebo rozšírenia k existujúcim implementáciám) každej spomínanej údajovej štruktúry, okrem ADT strom, ale aj stromy sa dajú reprezentovať použitím orientovaných acyklických grafov. GUAVA obsahuje aj implementácie základných stromových a grafových algoritmov. Rôzne užitočné statické metódy na prácu s údajovými štruktúrami nájdeme v triedach:
- Lists: karteziánsky súčin zoznamov, rozdeľovanie zoznamu na časti rovnakej veľkosti, prevrátenie poradia prvkov v zozname.
- Sets: rozdiel dvoch množín, prienik dvoch množín, zjednotenie dvoch množín.
- Maps: rozdiel dvoch zobrazení, filtrovanie a transformácia prvkov zobrazenia.
- Graphs: hľadanie cyklov v grafe, nájdenie všetkých vrcholov do ktorých sa dá dostať z daného vrcholu, prevrátenie orientácie hrán v grafe.
Guava má samostatnú verziu pre platformu Android. Táto verzia neobsahuje všetko, čo štandardná verzia, ale je optimalizovaná pre Android. Rozsah zdrojového kódu vo verzii pre Android je znížený a následne všetko je optimalizované pomocou nástroja ProGuard. Knižnica GUAVA je vhodná pre všetky typy projektov. Je flexibilná a ponúka mnoho možností, ktoré nie sú dostupné v ostatných knižniciach. Podľa údajov na stránke Maven Repository, GUAVA má viac ako dvadsaťtisíc použití. Triedy a metódy, ktoré ponúka, vedia vo veľkej miere uľahčiť prácu programátorov.
Apache Commons Collections
Commons Collections je open-source knižnica, ktorá rozširuje Java Collections novými rozhraniami a implementáciami údajových štruktúr. Okrem nových implementácií, zaujímavé sú aj triedy rozširujúce už existujúce implementácie z JC novými vlastnosťami:
- LazyList: keď dostane index väčší, ako kapacita zoznamu, nevyhodí výnimku, ale na požadované miesto vloží nový objekt, vytvorený továrenskou metódou.
- GrowthList: zvýši veľkosť zoznamu, ak dostane index väčší, ako kapacita zoznamu.
- SetUniqueList: neumožní vkladanie duplicitných prvkov do zoznamu.
Okrem zoznamov tu nájdeme aj niekoľko implementácií údajovej štruktúry multiset (množina, ktorá dovoľuje pridávanie duplicitných prvkov), slovník, multimap, bimap (zobrazenie, kde kľúče, ale aj hodnoty sú jedinečné). Z obsahového hľadiska, Commons Collections je postačujúca knižnica, ak potrebujeme použiť iba základné údajové štruktúry. Ponúka viac možností ako Java Collections, ale knižnica GUAVA je všestrannejšia a poskytuje viac údajových štruktúr.
JGraphT
JGraphT je knižnica špecializovaná na údajovú štruktúru graf, iné ani neposkytuje. Vychádza z teórie grafov, a pokryje pomerne veľkú časť tematiky (zo spomenutých knižníc najviac). Podporuje rôzne typy grafov, ako napríklad orientované, neorientované, hranovo-ohodnotené grafy, multigrafy, pseudografy a ešte mnoho ďalších. Čo sa týka grafových algoritmov, v JGraphT nájdeme implementácie algoritmov na farbenie grafov, vypočítanie toku v sieti, vypočítanie minimálnej kostry, najkratšej cesty, algoritmy súvisiace s cyklami a izomorfizmom. Okrem grafových algoritmov, v JGraphT môžeme nájsť aj implementáciu triediaceho algoritmu Radix sort, ktorá sa dá použiť na triedenie dlhých zoznamov celých čísel.
Výhodou JGraphT je, že umožňuje konvertovanie grafov z knižnice GUAVA pomocou adaptérov. JGraphT, podobne ako JUNG, tiež podporuje vizualizáciu grafov, ale nástroje na vizualizáciu nie sú zahrnuté priamo v knižnici. Autori odporúčajú knižnicu JGraphX na interaktívnu vizualizáciu grafov. Vizualizácia pomocou JGraphX je znázornená na nasledujúcom obrázku:
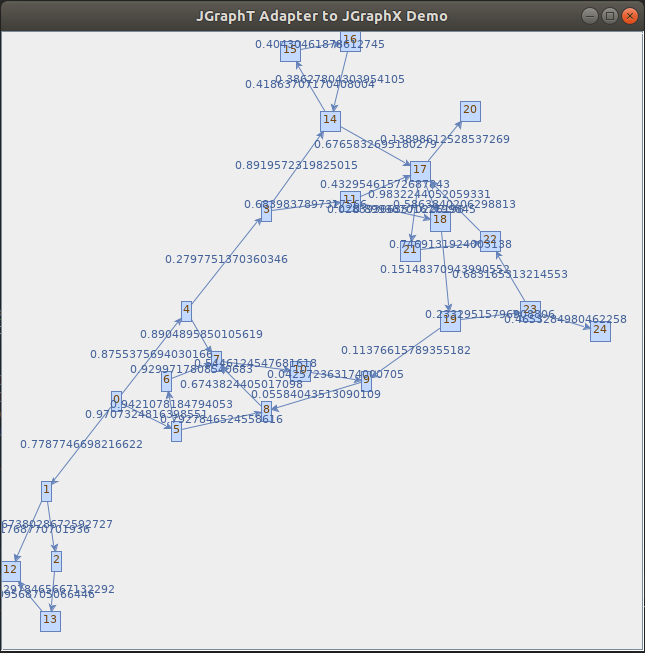
Z hľadiska vizualizácie, knižnica JUNG je výhodnejšia, lebo vizualizačné nástroje sú zahrnuté priamo v knižnici. Knižnica Vl-jung ponúka silné nástroje na interakciu s grafmi v reálnom čase, ja osobne by som odporúčal Vl-jung na vizualizáciu grafov.
Výsledky porovnania knižníc
V predchádzajúcich kapitolách boli opísané vybrané knižnice údajových štruktúr a algoritmov. V tejto kapitole sú zhrnuté výsledky porovnania výkonu implementácií z týchto knižníc. V nasledujúcej tabuľke sú uvedené názvy tried z jednotlivých knižníc, ktoré implementujú dané údajové štruktúry.
Zoznam
- JC
- ArrayList, LinkedList
- JDSL
- ArraySequence, NodeSequence
- CC
- TreeList
Z merania výkonu bolo zistené, že rozdiel medzi časmi vykonania operácií clear, size a isEmpty je veľmi malý, ale operácie, ktoré prechádzajú zoznam, alebo menia poradie prvkov v zozname, majú väčšie rozdiely. Implementácie z knižnice Java Collections dosiahli najlepšie výsledky vo väčšine operácií. Keď potrebujeme klasický zoznam na ukladanie objektov, tak trieda ArrayList je tá správna voľba. Implementácie z iných knižníc môžu byť vhodné v prípade ak používame aj iné údajové štruktúry z danej knižnice, a nechceme do nášho programu miešať triedy aj z iných knižníc, alebo keď potrebujeme zoznam na špecifický účel (napríklad TreeList na vkladanie/vymazávanie na základe indexov).
Množina
- JC
- HashSet, LinkedHashSet, TreeSet
- GUAVA
- HashMultiset, LinkedHashMultiset, TreeMultiset
- CC
- HashMultiSet
Meranie výkonu operácií nad údajovou štruktúrou množina bolo rozdelené na meranie výkonu klasických množín (implementácie iba z JC) a množín, ktoré podporujú duplicitné položky (multiset). Výkony implementácií ADT množina sú porovnateľné pri všetkých operáciách okrem remove a contains, kde TreeSet má výrazne väčší priemerný čas vykonávania. Čo sa týka implementácií ADT multiset, trieda TreeMultiset má najväčší čas vykonávania všetkých operácií okrem add. Najlepšie výsledky dosiahol HashMultiSet z knižnice CC. Zaujímavosťou je, že metódy size a isEmpty triedy TreeMultiset trvajú dlhšie, keď sú vykonané nad prázdnou množinou.
Prioritný front
- JC
- PriorityQueue
- JDSL
- ArrayHeap
- GUAVA
- MinMaxPriorityQueue
Z porovnaných implementácií najhoršie výsledky dosiahla trieda ArrayHeap z knižnice JDSL. PriorityQueue prekonal MinMaxPriorityQueue v operáciách insert a deleteMin, ostatné operácie majú len minimálne rozdiely z hľadiska výkonu. Napriek tomu, že ArrayHeap dosiahol najhoršie výsledky, má výhodu v tom, že poskytuje metódu replaceKey(Locator, Object), ktorou vieme zmeniť prioritu prvkov vo fronte. V prípade, keď je potrebné pristupovať k prvkom s najmenšou, aj s najväčšou prioritou, tak je vhodné použiť obojstranný prioritný front MinMaxPriorityQueue z knižnice GUAVA, ktorá túto funkcionalitu podporuje.
Slovník
- JC
- HashTable, HashMap, LinkedHashMap, TreeMap, WeakHashMap
- JDSL
- HashtableDictionary, RedBlackTree
- GUAVA
- ArrayListMultimap, TreeMultimap, HashMultimap
- CC
- HashedMap, LinkedMap, ArrayListValuedMap, HashSetValuedMap
Aj porovnanie výkonu implementácií ADT slovník bolo rozdelené na dve časti: meranie výkonu klasických slovníkov (k jednému kľúču priraďujú jednu položku) a slovníkov typu multimap (ku kľúču priraďuje kolekciu prvkov). Implementácie ADT slovník v knižnici JDSL môžu byť použité ako klasický slovník, alebo aj ako multimap, lebo majú definovanú operáciu find, ale aj operáciu findAll. Najmenší priemerný čas vykonania základných operácií má trieda LinkedHashMap z knižnice Java Collections. HashTable z JC dosiahol dobré výsledky v porovnaní s inými triedami, ale použitie tejto triedy sa podľa dokumentácie odporúča len vo viacvláknovom prostredí. Najhoršie výsledky dosiahli implementácie z knižnice JDSL. Implemenácie multimap nájdeme v knižniciach GUAVA a Commons Collections. Z hľadiska výkonu, triedy z CC sú vhodnejšie na použitie.
Strom a stromové algoritmy
| Stromy | Stromové algoritmy | |
|---|---|---|
| JDSL | NodeTree, NodeBinaryTree | PreOrderIterator, PostOrderIterator, InOrderIterator |
| JUNG | DelegateTree | |
| GUAVA | Traverser.depthFirstPreOrder(), Traverser.depthFirstPostOrder() |
Implementácie z knižnice JDSL nepodporujú operáciu depth na získanie hĺbky vrcholu. DelegateTree z knižnice JUNG nepodporuje operácie isEmpty a replace. Z výsledkov merania vyplýva, že výkony implementácií NodeTree a NodeBinaryTree sú porovnatelné, ale DelegateTree má výrazne vyšší čas vykonávania operácií parent, children a isRoot. Vzhľadom na výkon týchto implementácií, odporúča sa použiť triedy ponúkané knižnicou JDSL na reprezentovanie ADT strom, alebo ďalšia možnosť je použitie orientovaného acyklického grafu z knižnice GUAVA.
Čo sa týka stromových algoritmov, implementácie z knižnice JDSL dosiahli lepšie výsledky, čo môže byť pôsobené tým, že sú špecializované na ADT strom, kým implementácie z knižnice GUAVA pracujú s grafom. Ďalšou výhodou knižnice JDSL je, že zahŕňa implementácie pre každú stratégiu systematického označovania stromov (Preorder, Postorder, Inorder), kým knižnica GUAVA poskytuje iba metódy implementujúce stratégie Preorder a Postorder. Knižnica JDSL ponúka najviac možností pre prácu s ADT strom a aj jej výkon je lepší, ako knižnice GUAVA.
Graf a grafové algoritmy
| Grafy | Grafové algoritmy | |
|---|---|---|
| JDSL | IncidenceListGraph | DFS, IntegerPrimTemplate |
| JUNG | SparseGraph, SparseMultigraph | PrimMinimumSpanningTree |
| GUAVA | MutableValueGraph | Traverser.breadthFirst(), Traverser.depthFirstPreOrder(), Traverser.depthFirstPostOrder() |
| JGraphT | SimpleGraph, Multigraph | BreadthFirstIterator, DepthFirstIterator, BoruvkaMinimumSpanningTree, KruskalMinimumSpanningTree, PrimMinimumSpanningTree |
Knižnica JDSL zahŕňa iba jednu implementáciu ADT Graf: IncidenceListGraph. Táto jedna implementácia však podporuje veľké množstvo vlastností, ktoré sú v ostatných knižniciach implementované v osobitných triedach. Pomocou IncidenceListGraph vieme zostaviť grafy, obsahujúce orientované, aj neorientované hrany, prípadne aj slučky. V knižnici GUAVA rôzne vlastnosti grafu vieme nastaviť pri vytvorení grafu pomocou triedy GraphBuilder. GUAVA tiež podporuje orientované, neorientované grafy a grafy ktoré môžu obsahovať slučky. Knižnice JUNG a JGraphT sú zamerané na údajovú štruktúru graf. Názvy rozhraní, tried a metód v týchto knižniciach sú prebraté z teórie grafov. Obidve knižnice pokryjú veľkú časť grafových algoritmov.
Implementácie z knižníc GUAVA a JGraphT nepodporujú operáciu adjacent, ale poskytujú metódy na získanie kolekcie všetkých susedných vrcholov. Meranie výkonu bolo vykonané pre algoritmy BFS, DFS a hľadania minimálnej kostry grafu. Rozdiely vo výkone algoritmov BFS a DFS nie sú veľké. Z algoritmov hľadania minimálnej kostry grafu bola najrýchlejšia implementácia Kruskalovho algoritmu, z knižnice JGraphT. Najhorší výsledok dosiahla implementácia Primovho algoritmu z knižnice JUNG, ktorej trvala tá istá operácia trikrát dlhšie.
Triediace algoritmy
- JC
- Collections.sort(), Arrays.sort()
- JDSL
- ArrayMergeSort, ListMetgeSort, HeapSort, ArrayQuickSort
- JGraphT
- RadixSort
Z porovnaných knižníc najlepšie výsledky v meraní výkonu dosiahli implementácie zo vstavanej knižnice Java Collections. Zo všetkých algoritmov, Quick sort z knižnice JC bol najrýchlejší, ale ten sa používa iba pri triedení polí primitívnych typov. Pri triedení zoznamov, alebo polí objektov sa automaticky použije algoritmus TimSort. Implementácie z knižnice JDSL dosahovali rádovo horšie
výsledky, neodporúčajú sa použiť, iba v prípade keď je nutné pracovať so zoznamami z knižnice JDSL. Radix sort, implementovaný v knižnici JGraphT môže byť vhodný na triedenie zoznamov s veľkým množstvom prvkov. Táto implementácia je však obmedzená na triedenie zoznamov celých čísel (List<Integer>).
Vyhľadávacie algoritmy
Okrem vstavanej knižnice Java Collections, žiadna iná skúmaná knižnica neponúka implementácie vyhľadávacích algoritmov. Knižnica JC obsahuje implementáciu binárneho vyhľadávania pre zoznamy (v triede Collections) a pre polia (v triede Arrays). Metódy implementujúce binárne vyhľadávanie v zoznamoch môžu byť použité aj inými knižnicami, ktoré implementujú rozhranie List z Java Collections. Takéto implementácie ADT zoznam nájdeme v knižniciach GUAVA a Commons Collections.
Záver
Existuje mnoho knižníc, ktoré sa zaoberajú s tematikou údajových štruktúr a algoritmov, v tomto článku boli spomínané tie najrelevantnejšie. Každá knižnica má svoje výhody a nevýhody. O tom, ktorú použijeme v našom projekte, sa treba rozhodnúť podľa okolností a požiadaviek. Na záver, krátke zhrnutie zistených výhod, nevýhod a prípadov použitia spomenutých knižníc:
- Java Collections Framework: najvhodnejšia knižnica, keď je potrebné použiť iba základné údajové štruktúry. Implementácie sú dobre optimalizované, majú dobrý výkon.
- Data Structures Library for Java: táto knižnica sa odporúča použiť v prípade, ak je nevyhnutné využiť funkcionality, ktoré v ostatných knižniciach nie sú dostupné, inak je vhodnejšie použiť niektorú inú zo spomenutých knižníc, kvôli aktuálnosti.
- Java Universal Network/Graph Framework: knižnica vhodná na modelovanie a vizualizáciu grafov pomocou vstavaných nástrojov na vizualizáciu, alebo pomocou knižnice Vl-jung.
- Google Core Libraries for Java: ponúka najviac možností, je flexibilná, rozširuje knižnicu JC. Vhodná na použitie v rôznych projektoch.
- Apache Commons Collections: odporúča sa použiť v špecifických prípadoch, keď potrebná funkcionalita nie je dostupná v inej knižnici.
- JGraphT: najlepšia knižnica na reprezentovanie a prácu s grafmi. Obsahuje najväčšie množstvo grafových algoritmov a podporuje aj vizualizáciu pomocou knižnice JGraphX.