Projekt Online Superstore vznikol v rámci predmetu Tímový projekt. Našou úlohou bolo navrhnutie a vytvorenie internetového obchodu, zaoberajúceho sa predajom dámskeho oblečenia. Produkty pochádzali z niekoľkých amerických e-shopov, na ktorých „crawlovali“ naše webové crawlery niekoľkokrát denne. Vyzbierané dáta sme po spracovaní mohli na samotnom e-shope zobraziť našim potenciálnym zákazníkom. Jednou z podstatných funkcionalít nášho internetového obchodu je zobrazovanie doplňujúcich kúskov podľa typu prezeraného oblečenia. Práve táto myšlienka, spolu s našou tvrdou prácou, nám vyniesla 5. miesto na akcii Živé IT projekty.
Projekt vznikol ako myšlienka našich mentorov zo spoločnosti Affinity Analytics. Projekt ako taký bol pre nás veľkou výzvou. Mnoho študentov štvrtého ročníka už popri štúdiu pracuje v niektorej z košických IT firiem a má možnosť vyskúšať si prácu na veľkom projekte. Tieto skúsenosti následne vedia zúžitkovať na školských projektoch alebo v budúcich zamestnaniach. Vo väčšine prípadov však študenti nenesú na svojich pleciach zodpovednosť za celý projekt a nechávajú sa viesť skúsenejšími programátormi. Predmet Tímový projekt bol skvelou príležitosťou vyskúšať si vývoj na relatívne veľkom projekte od jeho analýzy, dizajnu a implementácie, až po jeho nasadenie. My sme boli tí, ktorí boli zodpovední za funkčnosť nášho riešenia a tak dokázali, že aj študenti majú na to, aby vytvorili funkčný prototyp riešenia komplexného zadania. V následujúcich riadkoch by sme vám radi ukázali, ako sme postavili náš internetový obchod s dámskym oblečením.
Rozdelenie projektu
Naša aplikácia sa skladala z 3 samostatných celkov - backend, frontend a crawlers. Backendová časť bola implementovaná v jazyku Java, s využitím rámca Spring Boot. Je napojená na databázový server MySQL. V backende sa nachádza logika stránky, funkcie pre konverziu javovských objektov na databázové entity, funkcie, ktoré zabezpečujú čítanie a zapisovanie do databázy a API rozhranie pre frontendovú a crawlerovú časť projektu.
Frontendová časť poskytuje používateľské rozhranie pre potenciálnych zákazníkov. Predstavuje ju webová aplikácia vyvíjaná v javascriptovskom rámci Angular 6. V aktuálnej verzii používateľovi ponúka možnosť prezerať si položky e-shopu podľa kategórií, podkategórií a typu udalosti, na ktoré sú dané položky vhodné. Umožňuje taktiež detailné zobrazenie jednotlivých produktov, kde používateľ vidí, v akých veľkostiach a farbách je produkt dostupný, fotky produktu, popis od predajcu a iné produkty, s ktorými je štýlovo možné daný produkt kombinovať. Zákazník má možnosť vybrať si produkty a pridať ich do košíka.
Poslednou časťou nášho projektu sú Web Crawlers (iné názvy: web scraper, web harvester, web spider). Pod pojmom crawler rozumieme internetového bota, ktorý systematicky prehľadáva webové stránky s cieľom získavania údajov z týchto stránok. Každá webová stránka má svoju vlastnú štruktúru, ako vonkajšiu (zoradenie položiek do kategórií, vlastnosti produktov), tak aj vnútornú (štruktúra HTML kódu, HTML elementy). Práve preto je potrebné pre každú stránku vyvinúť vlastný crawler. V našom projekte sme implementovali crawlery pre stánku www.toms.com a www.bcbg.com, na ktorých zbierajú údaje, upravujú ich do spracovateľného formátu a posielajú na backend. Ten ich následne zapíše do databázy.
Backend
Backendová časť bola v našom prípade zodpovedná za prenos údajov medzi crawlermi a web rozhraním. Náš backend nám poskytoval aj autentifikačný a autorizačný servis. Niektoré údaje, ako napríklad farby, neboli vždy poskytnuté pomocou crawlovania, bolo ich treba zapísať ručne, administrátorom. To isté platí aj o type udalosti, ku ktorej sa daný kúsok hodí. Z tohto dôvodu sme potrebovali vytvoriť rolu webového administrátora.
REST API
Najdôležitejšou časťou každého e-shopu, sú údaje, ktoré používateľ vidí a na základe ktorých sa rozhodne, či si daný tovar kúpi alebo nie. Tieto údaje je potrebné nášmu klientovi nejako poskytnúť. Zároveň je dôležité vedieť tieto údaje aj odniekiaľ získať. K tomuto účelu slúži jadro nášho projektu. Riešením bolo vytvorenie REST služby, ktorá dokázala prijímať údaje z jednej strany, spracovať ich, uložiť do našej databázy a následne v adekvátnej forme poskytnúť pre zobrazenie používateľom. Keďže sme sa chceli držať moderných technológií a využiť to, čo sme najlepšie poznali, rozhodli sme sa pre Java webový framework Spring Boot 2. Komunikáciu s databázou nám zabezpečili technológie Hibernate a JPA, o správu verzií a zostavovanie projektu sa nám staral Maven.
Databáza
V súčasnosti je na trhu množstvo databázových systémov, pričom každý má svoje plusy a mínusy. Nemali sme však ťažké rozhodovanie. Keďže sme už mali predošlé skúsenosti s databázou MySQL a pre naše účely úplne postačovala, výber bol jasný. Nasadená aplikácia s ňou fungovala ako hodinky. Čo však môže byť zaujímavejšie, je riešenie lokálneho vývoja. V tomto smere sme si uľahčili prácu, rozhodli sme sa použiť databázový engine H2, a pravdupovediac, všetci sme sa do práce s ním zamilovali. Čo je na ňom také úžasné?
Databázový engine H2 je zdarma a nepotrebujete si vďaka nemu nič inštalovať! H2 funguje tak, že emuluje vami zvolený databázový server, v našom prípade MySQL. H2 sme používali v móde „in-memory“ a teda nám vývoj nijako nezapratával naše disky, no zároveň nám plnohodnotne poskytoval všetky funkcionality MySQL servera. Ďalším aspektom tohto riešenia lokálneho vývoja bolo to, že po každom spustení sme mali „čistú databázu“, čo na jednej strane znamenalo nutnosť zakaždým ju napĺňať údajmi, na druhej strane však veľmi jednoduchý spôsob, ako sa zotaviť z chybných dát v databáze. Aby sme však stále mali nejaké korektné údaje, s ktorými môžeme pracovať, a nemusíme si zakaždým púšťať crawler, mali sme pripravené SQL skripty, pomocou ktorých sme po štarte aplikácie automaticky naplnili databázu. Hlavnou výhodou tohto riešenia bolo to, že crawler, ktorý sa nám staral o napĺňanie databázy údajmi, sa implementoval a „doťukával“ veľmi dlho a počas väčšiny vývoja by sme teda nemali odkiaľ čerpať tieto údaje.
Použitie tejto „in-memory“ databázy v spring-boote nie je nič zložité, stačí mať nastavený správny connector url v application.properties. V našom prípade to bolo:
domain.datasource.url=jdbc:h2:mem:superstore;MODE=MYSQL;DB_CLOSE_DELAY=-1
Testovacie dáta sme mali napísané vo forme SQL skriptov a spúštali sme ich pomocou spring konfigurácie (@Configuration). Táto konfiguračná trieda v sebe obsahovala vlastný Bean typu DataSource. Podľa typu databázy, získanej z application.properties sme vytvorili vlastný databázový zdroj. Ak išlo o H2 databázu, vykonali sme na nej skripty inicializácie schémy a vloženia testovacích dát.
@Bean
public DataSource dataSource() {
if (type.equals("MYSQL")) {
return DataSourceBuilder
.create()
.username(username)
.password(password)
.url(url)
.driverClassName(driverClass)
.build();
} else {
EmbeddedDatabaseBuilder builder = new EmbeddedDatabaseBuilder();
return builder
.setType(EmbeddedDatabaseType.H2)
.addScript("./database/schema.sql")
.addScript("./database/initialData.sql")
.build();
}
}
Použitá maven závislosť:
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
Autentifikácia a autorizácia
V neposlednom rade naša aplikácia poskytuje pre používateľov možnosť autentifikovať sa a tým pristúpiť ku svojmu nákupnému košíku, ku ktorému teda majú prístup kedykoľvek a kdekoľvek. Naša aplikácia taktiež rozlišuje užívateľa admin, ktorý má právomoci manipulovať s dátami.
Autentifikácia a autorizácia je v našej aplikácii riešená pomocou Spring security a JWT tokenov.
Frontend
Aplikácia mala byť implementovaná na webe, podporovaná viacerými zariadeniami od počítačov až po mobily. Keďže niektorí z náš už mali predošlé skúsenosti s rámcom Angular, pre našu webovú aplikáciu sme vybrali práve jeho. Ako väčšina moderných javascriptových rámcov, Angular poskytuje skvelé prostredie pre tvorbu komplexných klientských webových aplikácií. O klientskú logiku sa nám postará jazyk Typescript, ako modernejšia alternatíva Javascriptu. Hlavnú úlohu v tejto časti zohrával taktiež návrh používateľského rozhrania, keďže sme chceli vytvoriť používateľsky najprirodzenejšiu webovú aplikáciu. Pre jednoduchšiu prácu sme sa rozhodli použiť komponenty od PrimeNG.
Aplikácia v čase písania článku beží na serveri a je možné sa k nej dostať na adrese superstore.affinityanalytics.com:8090. Po načítaní sa zobrazí hlavná stránka, ktorá obsahuje údaje z backendu, ako môžeme vidieť na obr. 1. Tieto údaje sú zobrazované v tzv. „slideroch“, rozdelených podľa udalostí, a teda nakupujúcemu poskytujú radu, ktoré kúsky oblečenia sú s akými kombinovateľné.
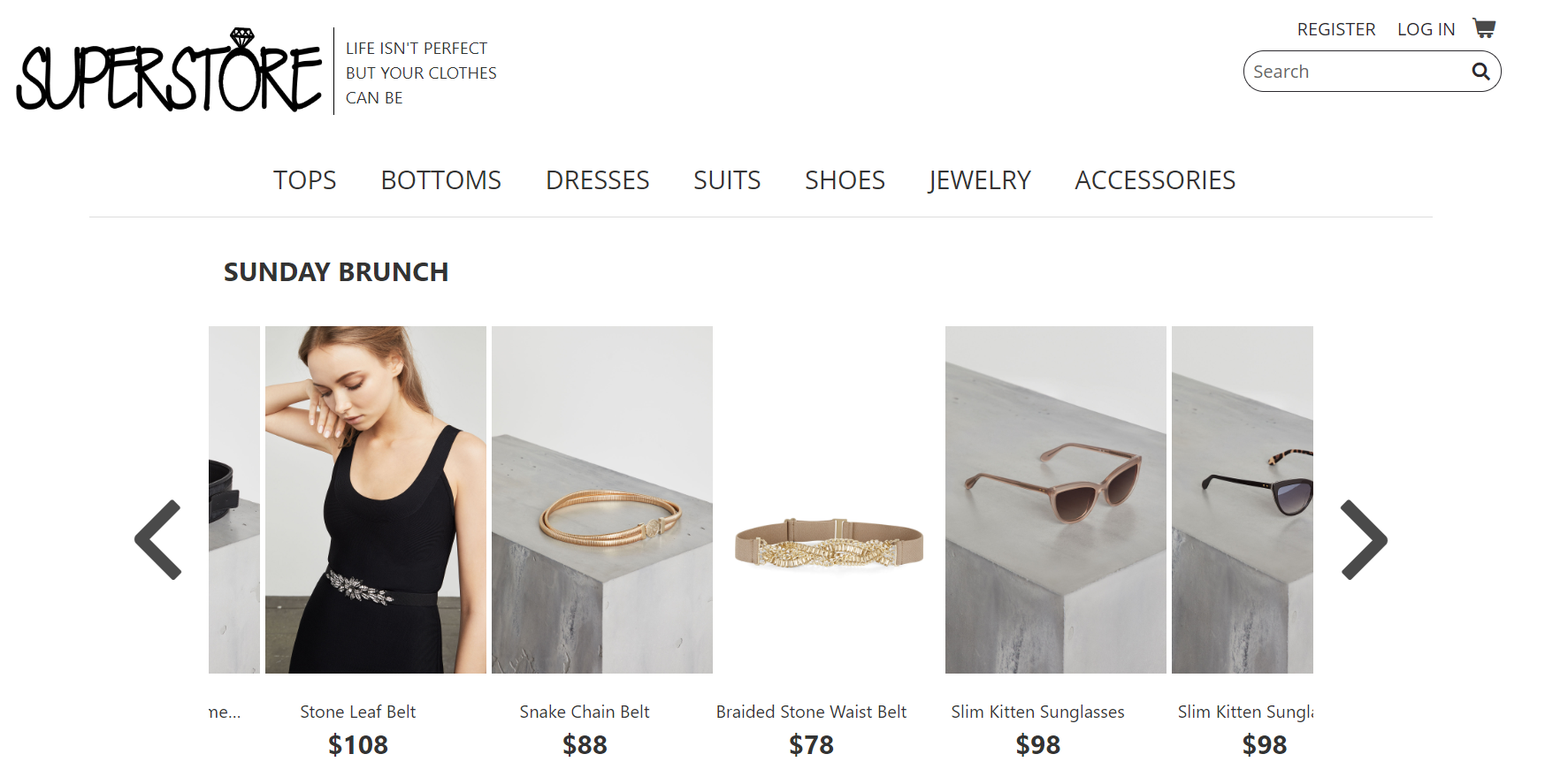
Táto časť stránky, ako aj každá iná, obsahuje hlavičku, v ktorej sa nachádza menu. V ňom sme si vybrali hlavné kategórie na základe crawlovaných stránok. Po kliknutí na niektorú z nich sa nám rozbalí podmenu s podkategóriami. Ak si nakupujúci vybral kategóriu, načíta sa mu stránka s jednotlivými produktmi, ako je zobrazené na obr. 2. Tieto produkty predstavujú reálne údaje z crawlovaných stránok s obrázkami, popismi, cenou, dostupnými veľkosťami, farbami a všetkým, čo by mal internetový e-shop poskytovať. Na ľavej strane sa nachádza filter, ktorý uľahčuje hľadanie produktu, ak vieme cenu, veľkosť a farbu akú hľadáme.
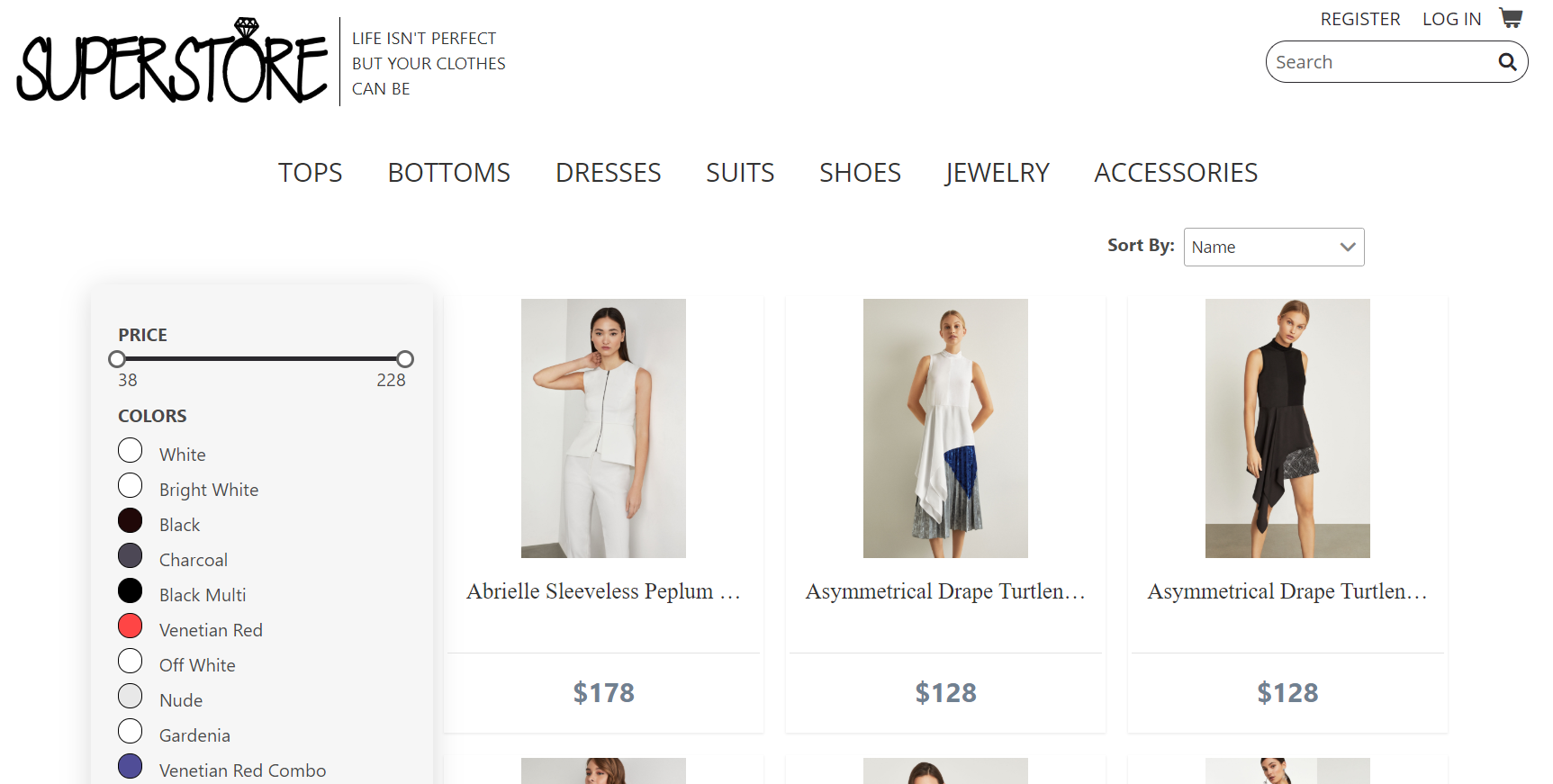
Ak nakupujúci našiel, čo hľadal, po kliknutí na produkt bude presmerovaný na jeho detail. Tu sa nachádzajú informácie o produkte v podobe reálnych dát. Obsahom sú obrázky z crawlovaných e-shopov, všetky dostupné veľkosti a farby produktu, cena, popis a podobne. Vymoženosťou tejto stránky webovej aplikácie sú taktiež tzv. „slidery“, ktoré slúžia ako „poradca“, ktorý bol robený priamo na frontende. Tento poradca ukazuje, aké kúsky oblečenia sa dajú kombinovať s vybraným produktom. Ak máme vybraté tričko, zobrazujú sa nám kombinovateľné kúsky z ostatných kategórií podľa udalostí, do ktorých patrí tričko. Následne, ak používateľ má vybraté oblečenie, stlačením tlačidla Add to cart, ktoré sa nachádza na stránke detailu, sa produkt presunie do nákupného košíka.
Nákupný košík využíva cookies, ak užívateľ nie je prihlásený a zobrazuje všetky produkty, ktoré sme doň pridali s ich cenou. Taktiež obsahuje výslednú cenu za všetky kusy oblečenia nachádzajúce sa v košíku. Ďalej ponúka tlačidlo Buy, ktorého funkcionalita v rámci tohto projektu nebola implementovaná. Implementácia tejto funkcionality nie je triviálna. Napadli nám dva spôsoby, ako by sa dala realizovať. Prvé riešenie by bolo kontaktovať správcov stránok jednotlivých e-shopov, a dohodnúť sa s nimi tak, aby účty našich používateľov platili aj na ich stránkach, teda preposielali by sme im záznamy z našej databázy používateľov. Druhé riešenie nevyžaduje spoluprácu s predajcami, ale zahrňovalo by automatické vytvorenie konta na každom e-shope pri registácii u nás. Táto funkcionalita by bola implementovaná v časti web crawlerov, kde by na základe šablóny a údajov, ktoré nám nový používateľ poskytol bol vytvorené účty, ku ktorým bude mať prístup iba naša aplikácia. Pri požiadavke nákupu by boli naplnené košíky daných e-shopov a vykonaná objednávka na pozadí. Problém predstavuje to, že na väčšine stránok je po registrácií nutné potvrdiť registráciu e-mailom, ktorý musí byť pre každého používateľa unikátny, čo predstavuje ďalšie kvantum práce pre web crawler.
Responzívne rozhranie
Ako už bolo spomenuté, aplikácia mala byť podporovaná na rôznych zariadeniach. Z toho dôvodu sme ju spravili čo najviac responzívnu. Existujú rôzne techniky a typy, ktoré by mal dizajnér a programátor dodržiavať pri návrhu stránky.
Najprv si naplánujte dizajn. Pred navrhnutím stránky je vhodné naplanovať rozloženie, obsah podstránok a zakresliť to na papier alebo použiť iný nástroj na to určený, čím sa vyhnete problémom pri budúcej implementácii.
Buďte opatrní s navigáciou. Navigácia je dôležitou súčasťou každej webovej stránky, je viditeľná všade, preto by mala obsahovať najvýstižnejšie údaje. Pri malých obrazovkách musia byť tie najdôležitejšie položky viditeľné a ostatné skryté pomocou hamburger menu.
Používajte Media Queries. Je to technika v CSS, ktorá využíva blok @media, v ktorom je možné na základe splnenej podmienky naštýlovať stránku, zmeniť, zakryť alebo odkryť nejaké elementy. Ako môžme vidieť na príklade v našej aplikácií po splnení podmienky max-width: 600px sa zmenia hodnoty atribútov triedy close na tie, ktoré sú definované v bloku @media.
.close {
float: left;
font-size: 5vw;
margin: -18px 95%;
}
@media screen and (max-width: 600px) {
.close {
font-size: 8vw;
margin: -18px 90%;
}
}
Používajte Grids a Breakpoints. Pri práci na dizajne stránky je možné použiť konštrukcie s gridom, ktoré dynamicky reagujú na zmenu zariadenia a upravujú čo a ako používateľ vidí na základe zariadenia a šírky prehliadača. Syntax sa líši v závislosti od použitia rámca, ale všeobecná koncepcia je rovnaká. Každá veľkosť zariadenia má zodpovedajúce media query a vlastnosti štýlu, ktoré vytvárajú požadovaný efekt rozloženia.
Pracujte s obsahom. Samozrejme je nutné zvoliť vhodný obsah stránky na základe cieľovej skupiny, pre ktorú je určená. Vhodne zvoliť obrázky, popisy a operácie nad týmito informáciami. Operáciami sa myslí, čo má byť ako zoradené, možnosť filtrovania na základe akých požiadaviek, čo sa zobrazí po kliknutí na nejaký element a podobne.
Využívajte rámce. Výber štandardného rámca, pre vytvorenie responzívneho webového dizajnu môže výrazne prispieť k úspechu projektu. Tieto rámce sú optimalizované pre rôzne zariadenia a ponúkajú širokú škálu predpripravených responzívnych elementov, ktoré zjednodušujú prácu a často robia dizajn stránky krajším.
Existujú aj ďalšie typy a triky na efektívny dizajn stránky, no týmito sme sa riadili aj my a názorná ukážka dizajnu je na obr. 2 reprezentujúca počítač a obr. 3 je z mobilného zariadenia, kde je možné vidieť prispôsobené rozhranie.
Rozhranie pre administrátora
Každý používateľ nášho e-shopu má uložený v databáze okrem mena, emailu a hesla aj údaj o tom, či je administrátor alebo nie. Administrátori nášho webu majú možnosť manažovať jednotlivé kusy oblečenia, t.j. priraďovať k nim farby, v ktorých sú produkty dostupné a udalosti, na ktoré sa dané produkty hodia. Administrátor má možnosť pridať, odobrať alebo upraviť názov typu udalosti. Tieto udalosti môže priraďovať ku jednotlivým položkám, prípadne odstrániť priradenie.
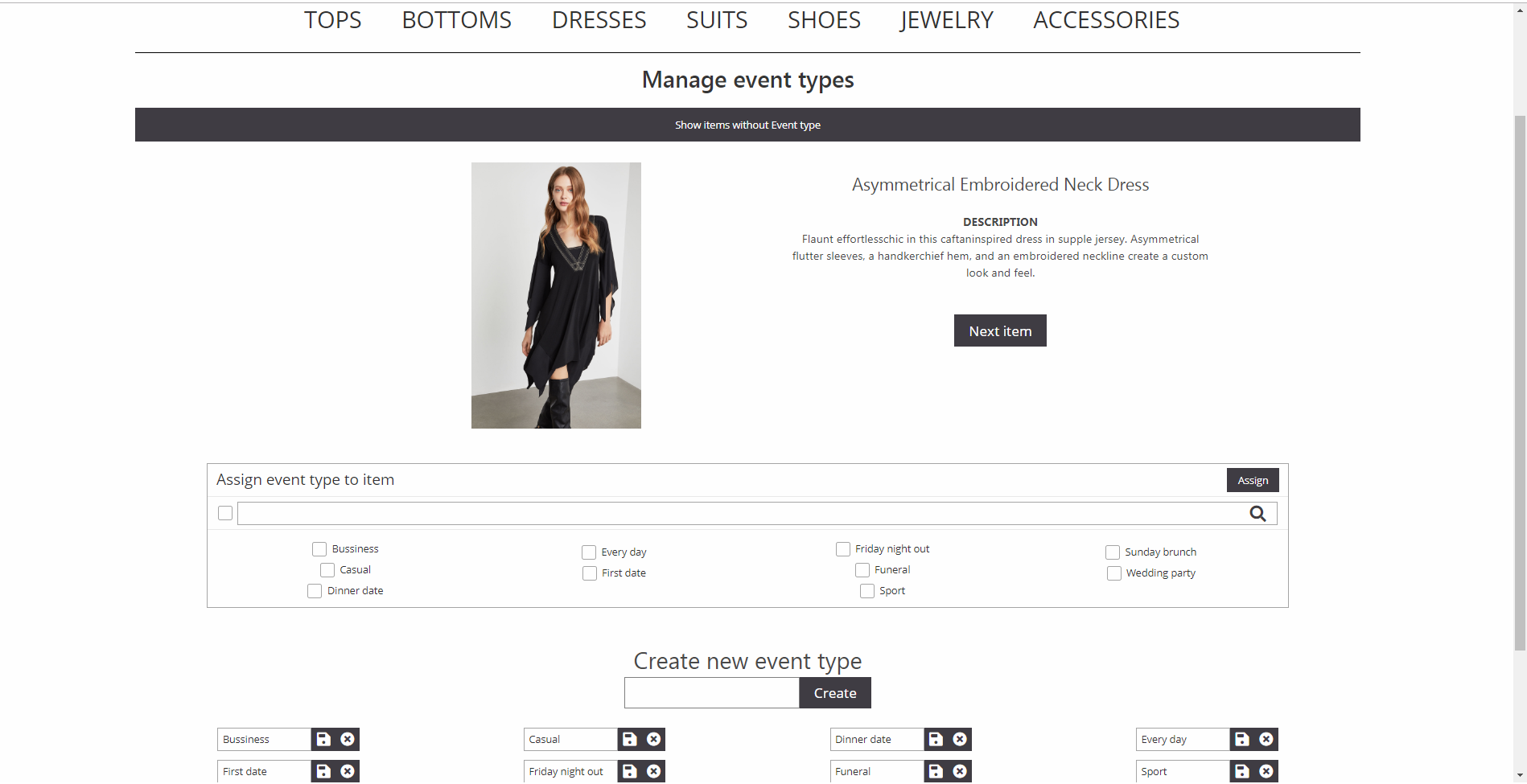
Tieto operácie sme potrebovali sprístupniť správcom nášho webu. Rozhodli sme sa ponúknuť im hneď niekoľko možností pre správu položiek. Správca má k dispozícií stránku, ktorá zobrazí všetky položky, ktoré ešte nemajú priradenú udalosť (zobrazenú rovnako ako kategória). Toto zobrazenie poskytuje prehľad o tom, aké nové produkty pribudli do ponuky (keďže novo pridané položky nemajú žiaden typ udalosti) a koľko tých produktov je. Pre samotné priradzovanie typov udalostí nie je toto zobrazenie optimálne, pretože po každej vybavenej položke sa musí vrátiť na zobrazenie položiek bez typu udalostí, kde si musí vybrať ďalšiu položku. Preto sme vytvorili rozhranie, ktoré správcovi postupne po jednom zobrazuje položky bez priradenej udalosti. Práca s týmto rozhraním je výrazne rýchlejšia. Prihlásený administrátor môže priraďovať udalosti aj cez „item-detail“ stránku položky kvôli tomu, aby mohol dodatočne upravovať priradenie udalostí položke, keďže položky s priradenou udalosťou sa už nezobrazujú v rozhraniach pre priradenie položky. Ukážka rozhrania pre vytváranie a priraďovanie udalostí je na obrázku 4.
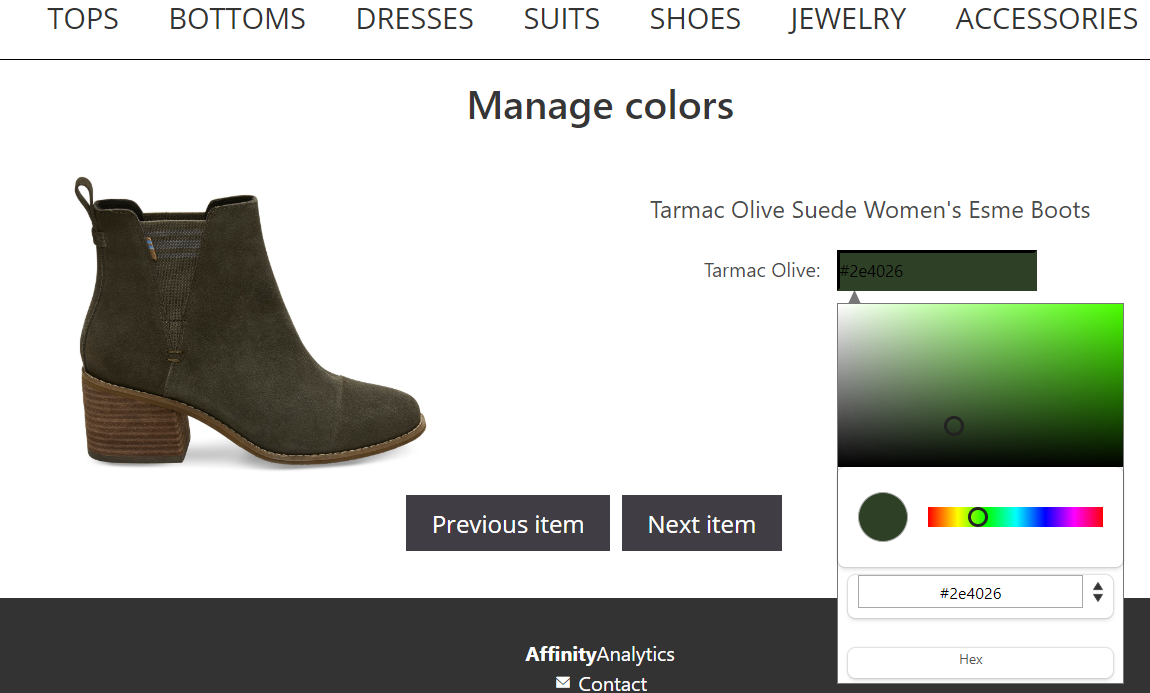
Na stránkach e-shopu mali jednotlivé položky farby vyjadrené kvetnatými popismi (napr. Tarmac Olive, Faded Rose alebo Black Cherry). My sme však potrebovali kód farby oblečenia, aby sme mohli ukázať farebnú vzorku vo filtri, a filtrovať položky podľa farieb. Na podobnom princípe ako rozhranie pre priradenie typu udalosti funguje aj rozhranie pre manažment farieb položky. Rozhranie postupne po jednom zobrazuje položky bez priradenej farby. Správca má k dispozícií collor picker, ktorý určí kód farby v hexadecimálnom tvare. Ak správca pozná kód farby, ktorý chce priradiť položke, môže ho zadať aj priamo, bez využitia collor picker-u. Ukážka rozhrania pre prideľovanie farieb je na obrázku 5.
Crawlery
Ako už bolo vyššie spomenuté, údaje do nášho e-shopu získavame pomocou crawlerov. Pre zjednodušenie vytvárania HTTP požiadaviek využívame proprietárnu knižnicu Net, ktorú nám poskytla firma Affinity. Táto knižnica bola obohatenou verziou obyčajného HTTP klienta, ktorá nám s ním v značnej miere zjednodušila prácu. Pomocou HTTP requestov získame HTML konkrétnych stránok a to si vieme jednoducho rozparsovať pomocou javovskej knižnice JSoup.
Už prvá požiadavka na ich hlavnú stránku nám odhalí mnoho informácii, ktoré následne využívame v ďalších požiadackách a takto sa “preklikávame” hlbšie a hlbšie až kým nenarazíme na konkrétne predmety, ktoré sa v danom obchode predávajú. Všetky údaje, ktoré potrebujeme k použitiu u nás vieme vyčítať z HTML elementov danej stránky. Tieto údaje si nakoniec ukladáme do našej databázy pomocou REST API na našom backende.
Pri vytváraní crawleru môžeme odporučiť použitie nástroja na debbugovanie webu ako napríklad Fiddler alebo aj Chrome DevTools, pomocou ktorého vieme zistiť obsah hlavičky HTTP požiadavky, kde sa môžu nachádzať dôležité informácie.
Ako prvú exemplárnu stránku sme si vybrali www.toms.com. Táto stránka nám poskytla miernu výhodu, keďže pre svoje fungovanie využíva JSON objekty, so všetkými informáciami o predávanom predmete. Tieto objekty sme si vedeli spracovať rýchlejšie a efektívnejšie. Druhou stránkou, www.bcbg.com, sme chceli našu ponuku trošku spestriť, keďže toms.com je zameraný hlavne na predaj topánok.
Crawlery sa spúšťajú automaticky, niekoľkokrát do dňa, čím sa zabezpečuje aktuálnosť našich údajov. V priemere nám získanie, prípadne aktualizácia 500 predmetov trvá 7 minút, samozrejme v závislosti od rýchlosti internetového pripojenia.
Nevýhodou takto postavených crawlerov je vysoká náchylnosť na chybu, keďže stačí mierna zmena na stránke e-shopu, odkiaľ čerpáme údaje a crawler je nutné upravovať.
Nasadenie
Funkčná aplikácia, ktorá beží vývojárovi na jeho počítači je síce pekná vec, veľkým problémov veľkých projektov je však nasadzovanie aplikácie do produkcie. Produkčné prostredie zvykne byť odlišné od našich osobných počítačov, či už v podobe odlišného operačného systému alebo iných softvérových záležitostí.

Docker
Ako sme už spomínali, snažili sme sa držať moderných technológií. Práve preto sme siahli po Dockeri. Ten robí z budovania a nasadzovania projektu jednoduchú a rýchlu vec. Docker je podporovaný na Linuxových operačných systémoch, aj na Windowse. Funguje na princípe kontajnerov. Zdrojové kódy spolu s ich závislosťami, knižnicami a inými nástrojmi sa zabalia do jednotného, štandardizovaného celku, ktorý je možné spustiť na akomkoľvek prostredí s rovnakým výsledkom. Rieši sa tým kompatibilita s rôznymi systémami a nemusíme sa teda báť žiadnych problémov pri nasadzovaní.
CI/CD
Moderné spôsoby nasadzovania aplikácií využívajú techniky, ako napríklad continuous integration (CI) alebo continuous delivery, resp. continuous deplyment (CD). Rovnako tomu bolo aj v našom prípade.
Continuous integration je v skrátene technika, pri ktorej sa pred nasadením aplikácie skontroluje, či novo pridané funkcionality nejakým spôsobom nenarušili funkčnosť celej aplikácie. Táto technika využíva automatické testovanie pri každom pokuse o budovanie zdrojového kódu do spustiteľnej aplikácie.
Continuous delivery je rozšírenie pre continuous integration, ktoré sa okrem automatického testovania postará aj o automatické nasadenie po úspešnom budovaní projektu a to všetko len na „jeden klik“.
Continuous deployment ide ešte o krok ďalej a vynecháva krok „jedného kliku“. Každá nová funkcionalita, ktorá bola pridaná do projektu sa postará o automatické nasadenie, pokiaľ nás nezastaví niektorý z testov. Pri tomto spôsobe nasadzovania treba byť obzvlášť opatrný a mať testy napísané čo najlepšie.
V našej aplikácii sme využili len prvú z techník a to continuous integration. Využili sme k tomu vstavanú podporu pre CI/CD potrubia (pipeline), ktorú nám poskytuje prostredie GitLab.
image: docker:latest
stages:
- build
- deploy
maven-build:
image: maven:3-jdk-8
stage: build
script:
- mvn clean package -DskipTests -P dev_mysql
artifacts:
paths:
- target/
expire_in: 2 hrs
only:
- master
deploy-latest:
stage: deploy
services:
- docker:dind
script:
- docker info
- docker login -u gitlab-ci-token -p $ACCESS_TOKEN git.kpi.fei.tuke.sk:4567
- docker build --pull -t $DOCKER_IMAGE:latest .
- docker push $DOCKER_IMAGE
only:
- master
Tento skript v jazyku YAML nám zabezpečí to, že sa nám náš zdrojový kód po pushnutí na GitLab automaticky skompiluje, vybuduje a vytvorí sa nám Docker kontajner. Tento Docker kontajner sa následne uloží v Docker repozitári. To, čo má náš Docker kontajner obsahovať, sa dozvieme zo súboru Dockerfile, ktorý sa taktiež musí nachádzať v projekte.
FROM simbiphp/oracle-java-8:latest
COPY target/online-superstore-0.0.1-SNAPSHOT.jar app.jar
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
Samotné nasadzovanie pomocou Docker kontajnerov sme robili ručne.
Na záver
Z predmetu Tímový projekt sme si toho veľa odniesli. Či už možnosť pričuchnúť k novým technológiám, alebo sa zdokonaliť v tých, ktoré sme už poznali. Mali sme možnosť vyskúšať si prácu v jednej z košických IT firiem — Affinity Analytics. Spoluprácu s nimi hodnotíme na výbornú. Stretávali sme sa každý týždeň na konzultáciách, prezentovali sme demo verziu našej aplikácie po každom týždennom šprinte. Stretnutia sa konali v priateľskej atmosfére a naši mentori mali vždy pochopenie, keď sme mali aj iné školské povinnosti a nestíhali sme. Ich programátori boli vždy ochotní poradiť nám, keď sme si nevedeli dať s niečím rady.
Dokonalé riešenie
Čo sa týka projektu ako takého, musíme úprimne povedať, že nie všetko je také dokonalé, ako sa môže na prvý pohľad zdať. Splnili sme si ciele, ktoré sme si na začiatku zadali. E-shop bol, čo sa týka prehliadania produktov a manipulácie s nimi, funkčný a podľa nášho názoru, aj celkom pekný a prehľadný. Aj keď to tak nevyzerá, postaviť internetový obchod za jeden semester dá celkom zabrať, hlavne keď sa do toho pustí partia študentov, ktorá tomu samozrejme nemôže venovať 8 hodín denne.
Aplikácia má samozrejme svoje nedostatky. Jedným z najväčších, je podľa nášho názoru rýchlosť načítavania. Bohužiaľ, na nejakú optimalizáciu jednoducho neostal čas. Aplikácia by sa dala jednoznačne optimalizovať použitím lazy loadingu, t.j. načítavanie položiek po dávkach a nie všetky naraz. Ďalšou možnosťou by bolo použitie obrázkov s menším rozlíšením na stránkach, ktoré obsahujú viacero položiek. Veľkou pomocou by bola rozhodne pamäť cache, ktorá by zabránila zbytočnému načítavaniu už načítaných položiek.
Čo sa týka crawlerov, pre každého z nás to bolo prvé stretnutie s touto technológiou. Podarilo sa nám ich úspešne implementovať, avšak ich najväčším problémom je neustále sa meniaca štruktúra „crawlovaných“ e-shopov. Z tohto dôvodu by bolo treba naše crawlery pravidelne kontrolovať a meniť ich podľa aktuálnej verzie externých e-shopov.
Ako uspieť na tímovom projekte
Pre budúce ročníky, ktoré sa budú účastniť tímových projektov rozhodne odporúčame dobre si rozmyslieť, s akou firmou budete spolupracovať. Skúste sa informovať u predošlých ročníkov, ktorá z ponúkaných spoločností si vie nájsť čas na stretnutia a je ochotná poradiť a pomôcť.
Dôležitým faktorom je však samozrejme vybrať si tému, ktorá vás zaujme. Nie je nič horšie, ako pracovať na niečom, čo vás nezaujíma. My sme si tému vyberali podľa použitých technológií. Všetci členovia tímu boli ochotní pustiť sa do vývoja webovej aplikácie a tým pádom to pre nás nebolo „ako za trest“.
Posledným, azda najdôležitejším odporúčaním je začať hneď od prvého týždňa! Tímovému projektu sme venovali veľmi veľa času, zabral nám väčšinu semestra, a práve prvé týždne sú ešte tie „voľnejšie“. Máte čas dostatočne rozpracovať vaše riešenie natoľko, že budete stíhať ostatné predmety a nedostanete sa do časového stresu.