Tento článok má za úlohu ukázať použitie nástrojov ANTLR a YAJCo na vývoj syntaktického analyzátora počítačového jazyka. Obidva nástroje sú generátory jazykových procesorov, ale využívajú rozdielne postupy na tvorbu jazykov.
Úvod
ANTLR4 je generátor jazykových procesorov, ktorý sa môže použiť na čítanie, spracovanie, vykonanie alebo preloženie štruktúrovaných textových alebo binárnych súborov. Je široko využívaný na tvorbu rôznych jazykov, nástrojov a frameworkov. ANTLR generuje syntaktický analyzátor z gramatiky jazyka, tento analyzátor automaticky vytvára stromy odvodenia z prečítaného textu. ANTLR taktiež generuje moduly na prechádzanie stromu, ktoré sa používajú na prejdenie jednotlivých uzlov stromu a vykonanie určitého kódu.
YAJCo je generátor jazykových procesorov, ktorý pracuje s doménovým modelom napísaným v jazyku Java. Tento model obsahuje anotácie, ktoré slúžia na definovanie detailov, ktoré nie je možné získať zo vzťahov medzi triedami alebo zo samotných tried. V súčasnej implementácii YAJCo generuje gramatiku pre generátory JavaCC a Beaver, tieto generátory následne vygenerujú syntaktický analyzátor. Taktiež dokáže vygenerovať modul na prechádzanie stromu, ktorý implementuje návrhový vzor návštevník (visitor).
Na ilustráciu použitia obidvoch nástrojov bude v tomto návode opísaný postup vytvorenia syntaktického analyzátora pre jazyk Logo Tortue.
Logo Tortue
Tortue Logo je jeden z mnohých druhov implementácie doménovo-špecifického jazyka Logo. Tento jazyk je určený hlavne na výučbu programovania pre deti. Pomocou viet v tomto jazyku je možné ovládať korytnačku, ktorá svojim pohybom kreslí obrázky. Opis všetkých príkazov jazyka sa nachádza v jeho dokumentácii. Ukážka kódu:
TO DRAWSQUARE
REPEAT 4
FORWARD 50
LEFT 90
END REPEAT
END TO
CLEAR
HOME
PENCOLOR RED
REPEAT 6
DRAWSQUARE
RIGHT 60
END REPEAT
Výsledkom vykonania daného kódu je takýto obrázok:
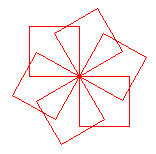
Objektový model jazyka
Na začiatku implementácie je potrebné vytvoriť objektový model jazyka, ktorý bude použitý pri obidvoch nástrojoch. Model jazyka je reprezentovaný triedami v jazyku Java a predstavuje vlastne abstraktnú syntax jazyka. Objekty týchto tried sa vytvoria počas syntaktickej analýzy vstupného textu a použijú sa na ďalšie spracovanie — vykreslenie výsledného obrázka.
Pri použití nástroja ANTLR4 sa potom definuje gramatika jazyka vo forme EBNF, z ktorej sa vygeneruje syntaktický analyzátor, a implementuje sa naplnenie modelu. Pri implementácii s nástrojom YAJCo sa do modelu pridajú anotácie, ktoré definujú konkrétnu syntax a na základe nich sa generuje syntaktický analyzátor.
Koreňovou triedou modelu je trieda Logo, ktorá obsahuje zoznam príkazov (Command). Command je rozhranie, ktoré je implementované abstraktnou triedou SimpleCommand a triedou Function. Function nemôže dediť od SimpleCommand, aby nebolo možné vložit do definície príkazu dalšiu definíciu príkazu. Od triedy SimpleCommand potom dedia ostatné príkazy. Špeciálnymi príkazmi sú IF, REPEAT a TO, ktoré obsahujú iné príkazy. Príkaz TO slúži na definovanie vlastného príkazu, ktorý sa potom môže zavolať niekde v kóde pomocou názvu.
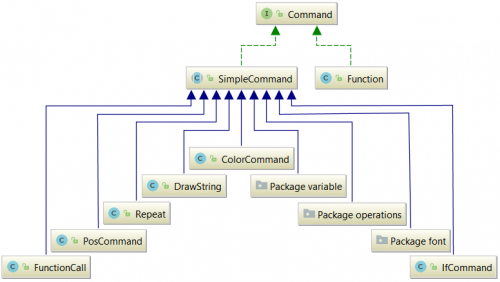
Implementácia s využitím nástroja ANTLR je v projekte logo_antlr a s nástrojom YAJCo v projekte logo_yajco.
Pridanie závislostí
Aby bolo možné používať spomínané nástroje je nutné pridať závislosti v nástroji maven. Závislosti pre anotačný procesor a generátor gramatiky pre Beaver potrebné pre nástroj YAJCo:
<dependency>
<groupId>sk.tuke.yajco</groupId>
<artifactId>yajco-annotation-processor</artifactId>
<version>0.5.9</version>
</dependency>
<dependency>
<groupId>sk.tuke.yajco</groupId>
<artifactId>yajco-beaver-parser-generator-module</artifactId>
<version>0.5.9</version>
</dependency>
Závislosť potrebná pre nástroj ANTLR4:
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-maven-plugin</artifactId>
<version>4.7</version>
</dependency>
V prípade ANTLR4 je dobre použiť aj rozšírenie na zvýraznenie syntaxe gramatiky, aby sa lepšie čítala. Projekt bol vyvíjaný vo vývojovom prostredí IntelliJ IDEA, pre ktorý existuje rozšírenie “ANTLR v4 grammar plugin”. Podobné rozšírenia sú aj pre ďalšie najpoužívaniejšie vývojové prostredia pre jazyk Java ako NetBeans IDE a Eclipse.
Implementácia analyzátora
Vo väčšine prípadov vstupná veta jazyka prechádza cez lexikálnu a syntaktickú analýzu. V lexikálnej analýze sa vstupná veta rozdelí na tokeny (symboly definované v gramatike). Nasleduje syntaktická analýza, ktorá kontroluje, či je splnená správna postupnosť tokenov a vytvára abstraktný syntaktický strom.
ANTLR
Na definovanie konkrétnej syntaxe v nástroji ANTLR slúži gramatika vo forme EBNF, z ktorej sa následne vygeneruje lexikálny a syntaktický analyzátor. Pri tvorbe gramatiky sa rozlišujú lexikálne a syntaktické pravidlá. Lexikálne pravidlá musia byť napísané v poradí, v akom majú byť vyhodnocované, aby lexikálny analyzátor správne určil aký token má vytvoriť.
Gramatika pre jazyk Logo je nasledovná:
grammar Logo;
logo: (command | to | NEWLINE) (NEWLINE+ (command | to | EOF))*;
command: pos_command | pen_color | can_color | font_name | font_size | font_style
| make_var | content_var | operation | repeat | if_command | draw_string
| simple_command;
simple_command: SIMPLE | name;
pos_command: POS_COMMAND value;
pen_color: 'PENCOLOR' (COLOR | value value value value);
can_color: 'CANVASCOLOR' (COLOR | value value value);
font_name: 'FONTNAME' FONT;
font_size: 'FONTSIZE' NUMBER;
font_style: 'FONTSTYLE' STYLE;
make_var: 'MAKE' name '=' value;
content_var: 'CONTENT' name;
draw_string: 'DRAWSTRING' text;
text: (~NEWLINE)+;
operation: sum | subtract | divide | multiply;
sum: 'SUM' name '=' value '+' value;
subtract: 'SUBTRACT' name '=' value '-' value;
divide: 'DIVIDE' name '=' value '/' value;
multiply: 'MULTIPLY' name '=' value '*' value;
repeat: 'REPEAT' value NEWLINE+ (command (NEWLINE+ command)* NEWLINE+)? 'END REPEAT';
to: 'TO' name NEWLINE+ (command (NEWLINE+ command)* NEWLINE+)? 'END TO';
if_command: 'IF' value COMP_SYMBOL value NEWLINE+
(command (NEWLINE+ command)* NEWLINE+)? 'END IF';
value: name | NUMBER;
name: NAME | COLOR | POS_COMMAND | SIMPLE | FONT | STYLE;
COMP_SYMBOL: '=' | '>' | '<' | '!';
POS_COMMAND: 'FORWARD' | 'BACKWARD' | 'LEFT' | 'RIGHT' | 'SETX' | 'SETY';
SIMPLE: 'PENDOWN' | 'CLEAR' | 'HOME' | 'NEW' | 'PENUP';
COLOR: 'BLACK' | 'BLUE' | 'CYAN' | 'DARKGRAY' | 'GRAY' | 'GREEN' | 'LIGHTGRAY'
| 'MAGENTA' | 'ORANGE' | 'PINK' | 'RED' | 'WHITE' | 'YELLOW';
FONT: 'DIALOG' | 'DIALOGINPUT' | 'MONOSPACED' | 'SERIF' | 'SANSSERIF' | 'SYMBOL';
STYLE: 'PLAIN' | 'BOLD' | 'ITALIC';
NUMBER: [0-9]+('.'[0-9]+)?;
NAME: [a-zA-Z._]+;
WS: [\t ] -> channel(HIDDEN);
NEWLINE: [\r]?[\n];
Zaujímavými pravidlami sú text a WS. Pomocou znaku “~” je v pravidle text definované, že môže obsahovať každé lexikálne pravidlo okrem pravidla NEWLINE pre nový riadok. Lexikálne pravidlo WS určuje, že všetky medzery alebo tabulátory majú byť preskočené. V tomto prípade je použitý channel(HIDDEN), ale namiesto toho sa môže použiť aj skip - WS: [\t ] -> skip.
Na naplnenie modelu ANTLR vygeneruje pomocný modul na prechádzanie stromu, ktorý môže implementovať návrhový vzor poslucháč (listener) alebo návštevník (visitor). Nástroj ANTLR s predvoleným nastaveniami vygeneruje modul využívajúci vzor poslucháč, ak chceme použiť návrhový vzor návštevník je potrebné dodatočne nastaviť túto možnosť.
Naplnenie modelu implementované pomocou návrhového vzoru poslucháč je realizované v triede LogoCreator. Pri tejto implementácii sa prechádza strom odvodenia vytvorený na základe analyzovaného textu a automaticky sa volajú metódy pri vstupe a výstupe z uzlov stromu zodpovedajúcich jednotlivým syntaktickým pravidlám. Objekty zodpovedajúce jednoduchým príkazom sa vytvárajú už pri vstupe do ich pravidla, ale objekty pre príkazy IF, REPEAT a TO musia byť vytvorené až pri výstupe z ich pravidla. Dôvodom je to, že obsahujú zoznam iných pravidiel, ktoré je potrebné najprv vytvoriť a až tak je možné vytvoriť samotný príkaz obsahujúci zoznam. Kvôli týmto zoznamom je nutné rozlišovať, do ktorého sa vloží práve vytváraný príkaz. Preto sa pri naplňovaní modelu používa jeden základný zoznam príkazov a zásobník zoznamov. Pri vstupe do niektorého z týchto troch príkazov sa vytvorí nový zoznam príkazov a vloží sa do zásobníka. Ostatné príkazy sa vytvárajú priamo pri vstupe do zodpovedajúcich uzlov. Po vytvorení sa príkaz vloží do posledného zoznamu v zásobníku alebo do základného zoznamu, ak je zásobník prázdny.
Pri implementácii pomocou návrhového vzoru návštevník (trieda LogoVisitorCreator) sa metódy nevolajú automaticky ale je potrebné ich volať explicitne. Vytváranie jednoduchých príkazov je implementované rovnako ako pri návrhovom vzore poslucháč, ale s tým rozdielom že metóda na navštívenie príkazu má návratovú hodnotu podľa príkazu, ktorý sa vytvára. Pri navštívení príkazov IF, REPEAT a TO sa vytvorí aj zoznam príkazov, ktoré obsahujú tak, že sa postupne navštívia jednotlivé metódy pre príkazy, ktoré je potrebné vytvoriť. Taktiež implementácie rekurzie je jednoduchšia, pri vytváraní vlastného príkazu sa najprv vytvorí inštancia objektu Function s prázdnym zoznamom príkazov, následne sa vytvárané príkazy vkladajú do tohto zoznamu. Týmto je zabezpečené, že vlastný príkaz je rozpoznaný aj pri volaní z jeho definície.
Nasledujúca ukážka obsahuje príkazy potrebné na spracovanie vstupu pomocou jazykového procesora vygenerovaného nástrojom ANTLR:
InputStream in = new FileInputStream(file);
LogoLexer lexer = new LogoLexer(CharStreams.fromFileName());
CommonTokenStream tokens = new CommonTokenStream(lexer);
LogoParser parser = new LogoParser(tokens);
LogoVisitorCreator analyzer = new LogoVisitorCreator(parser);
Logo logo = analyzer.visitLogo(parser.logo());
Oproti úplnému projektu je v ukážke vynechaná zmena celého vstupu na veľké písmena a interpretátor, ktorý vykoná príkazy prečítané zo vstupu a vykresli výsledný obrázok.
YAJCo
Pri implementácii v nástroji YAJCo sa konkrétna syntax definuje pomocou anotácií v modeli. Vstupná veta sa najskôr rozdelí na tokeny definované v súbore package-info.java v anotácii @Parser pomocou anotácií @TokenDef. Príklad definovaného tokenu pre názov premennej vyzerá takto @TokenDef(name = "NAME", regexp = "[a-zA-Z]+"). V anotácii @Parser sa môžu okrem definícií tokenov definovať aj znaky na preskočenie (@Skip) a iné možnosti pre generovanie (@Option).
Ostatné anotácie sa zapisujú priamo do tried doménového modelu. Ako príklad môžu slúžiť triedy ContentVariable a Name.
public class ContentVariable extends SimpleCommand {
private Name name;
@Before("CONTENT")
@After("EOL")
public ContentVariable(Name name) {
super("CONTENT");
this.name = name;
}
}
public class Name {
private String name;
public Name(String name) {
this.name = name;
}
@FactoryMethod
public static Name colorName(@Token("COLOR") String name) {
return new Name(name);
}
}
Každý konštruktor alebo metóda označená anotáciou @FactoryMethod slúži ako pravá strana syntaktického pravidla v gramatike. Trieda Name je pomocnou triedou, ktorá bola pridaná, aby názvy farieb, reprezentované tokenom COLOR, sa mohli použiť ako meno premennej. Ako vidieť na ukážke z tejto triedy jeden konštruktor spracuje token NAME a inicializačná metóda spracuje token COLOR. V konštruktore nie je nutné použiť anotáciu @Token pretože meno premennej je rovnaké ako meno tokenu. V triede ContentVariable sú použité anotácie @Before a @After, pomocou ktorých je určené, že pred menom premennej má byť kľúčové slovo CONTENT a príkaz má byť ukončený novým riadkom (EOL).
Oproti implementácii v nástroji ANTLR musel byť model upravený. Okrem už spomínanej pomocnej triedy Name boli pridané triedy CanvasColor a PenColor, ktoré dedia od triedy ColorCommand, ktorá bola zmenená na abstraktnú triedu.
Nástroj YAJCo, na rozdiel od ANTLR, naplní model automaticky. Okrem základného naplnenia modelu tento nástroj zvláda aj referencie pomocou anotácií @Identifier a @References. V projekte pre jazyk Logo boli tieto anotácie použité pre rozpoznanie používateľom definovaného príkazu.
public class Function implements Command {
@Identifier
private String name;
private List commands;
...
}
public class FunctionCall extends SimpleCommand {
private Function function;
@After("EOL" )
public FunctionCall(@References(value = Function.class) String name) {
super(name);
}
...
}
Pre použitie jazykového procesora vygenerovaného nástrojom YAJCo je potrebné použiť nasledujúce príkazy:
Parser parser = new Parser();
File file = new File();
FileReader reader = new FileReader(file);;
Logo logo = parser.parse(reader);
Toto je základný príklad, v projekte je možné vidieť aj vytvorenie interpretátora, ktorý spracuje vstupnú vetu, ktorá je reprezentovaná objektom Logo. Pri akejkoľvek zmene v anotáciách je nutné spustiť príkazy clean a compile nástroja maven pre vygenerovanie jazykového procesora.
Záver
Na príklade implementácie jazyka Tortue Logo bola vysvetlená práca s nástrojmi YAJCo a ANTLR. Keďže gramatika ANTLR v príklade využíva len jednoduché pravidlá, môže byť užitočné pozrieť si dokumentáciu. V prípade nástroja YAJCo sú ďalšie informácie v používateľskej príručke, kde je možné nájsť aj ďalšie príklady.