V článku prejdeme procesom spracovania dát v skriptovacom jazyku Python a ich následnou vizualizáciou. S využitím knižníc ako NumPy, Matplotlib a Matplotlib Basemap bude demonštrovaná tvorba viacerých variácií vizualizácií dát. Či už v podobe bežných grafov, vykreslením dát na projekcii mapy Zeme alebo 3D vizualizáciou.
Krátke predstavenie jazyka Python
Vysoko-úrovňový všestranný skriptovací programovací jazyk Python má širokú škálu aplikovateľnosti vo svete informatiky. Medzi jeho prednosti patrí okrem iného jednoduchá syntax a efektívnosť písania kódu oproti jazykom ako napríklad Java, C alebo C++. Taktiež má k dispozícií nespočetné množstvo knižníc, ktoré rozširujú funkcionalitu samotného jazyka a prispievajú k jeho všestranosti. Jednou z takýchto knižníc je práve knižnica Matplotlib o ktorej si povieme neskôr v príspevku.
V súčasnosti jedným z najobľúbenejších vývojových prostredí pre vyvíjanie v jazyku Python je PyCharm vyvíjaný českou spoločnosťou Jetbrains. PyCharm je dostupný na všetkých dominantných operačných systémoch ako Windows, macOS a Linux, a ponúka efektívnu analýzu kódu, debugger, integrované spúšťanie jednotkových testov, správu verzií a podobne.
Konkurencia vo svete Data Science?
Jazyk Python spolu s jazykom R patria medzi dva najhlavnejšie nástroje pre Data Science a vizualizáciu dát. Samotný jazyk R bol vytvorený špecificky pre potreby komunity zaoberajúcej sa dátovou analýzou a štatistikou. Avšak navzdory tomu je univerzálnosť Pythonu silným konkurentom pre jazyk R.
Podľa súčasných trendov a prieskumu zo Septembra 2017, vykonaného vedúcou webovou stránkou KDnuggets o Data Science, Big Data, Machine Learning a podobne, môžeme vidieť, že jazyk Python má prevahu v škále aplikovateľnosti a popularity oproti jazyku R. Jedným z dôvodom je aj fakt, že jazyk Python sa dá priamo použiť v širšom svete a projektoch, než jazyk R, ktorý slúži iba na samotnú analýzu dát a Data Science. Avšak to neznamená, že tieto dva jazyky si konkurujú do miery, kde sa používa iba jeden alebo druhý. Ako tomu býva vo svete informatiky, správne nástroje sa vyberajú podľa okolností a ktokoľvek kto má seriózny záujem o Data Science by mal byť schopný pracovať v obidvoch jazykoch, keďže mnohokrát sa stáva, že jazyky Python a R sa navzájom dopĺňajú vo svojich činnostiach.
Základy jazyka Python
Hello Python a prvé kroky
Základom pre naučenie sa nového programovacieho jazyka je oboznámenie sa s jeho syntaxou. Na rýchlo si prejdeme základné prvky syntaxe jazyka Python, ktorý zdieľa isté podobnosti s jazykmi ako Java, C, Perl a podobne, ale stále obsahuje rozdiely, ktorým je potrebné venovať pozornosť.
Pri práci s Pythonom môžeme pracovať buď v Python konzole alebo interpretátoru dodáme súbor so skriptom, v ktorom vykoná každý príkaz až do konca súbora.
Začnime od základného vypísania do konzoly, ktoré dosiahneme volaním funkcie print():
print("Hello Python!")
Výstupom z takéhoto príkazu je vypísanie reťazca „Hello Python!“ do konzoly. Pre úplnosť, v starších verziách jazyka bola funkcia „print()“ v podobe príkazu, tj. print “Hello Python!" namiesto print(“Hello Python!"). Premena na funkciu nastala vo verzie Python 3.0.
Taktiež je nutné spomenúť, že Python je citlivý na odsadzovanie kódu, keďže kód nevyužíva zátvorky na ohraničenie kódu, ako tomu je napríklad v jazyku Java alebo C. Príklad takejto citlivosti na odsadzovanie si môžeme ukázať na nasledujúcom príklade, kde si vysvetlíme ako funguje priradenie hodnôt premenným, komentovanie a príkaz „if-elif-else“.
# Komentár v kóde sa vytvorí napísaním komentára
# za znak "#" na hociktorom mieste v kóde.
# Do premennej "verzia" uloží hodnotu integer.
verzia = 3
# Premennú "verzia" dokážeme prepísať na akýkoľvek dátový typ.
verzia = "3"
jazyk = "Python"
# Tu môžeme vidieť ako jazyk Python požaduje odsadzovanie kódu.
# Odsadenie v tomto prípade spĺňa funkciu rovnakú ako zátvorky v iných jazykoch.
if verzia == "3":
print("Tento reťazec bol vytvorený v jazyku %s verzie %s.X." % (jazyk, verzia))
elif verzia == "2":
print("Tento reťazec bol vytvorený v jazyku %s verzie %s.X." % (jazyk, verzia))
else:
print("ERROR")
V kóde si môžete všimnúť, že nikde nie je deklarovaný dátový typ premenných. Oproti staticky typovaným jazykom, ako Java alebo C, je Python dynamicky typovaný jazyk, tj. dátové typy premenných nie sú statické a môžeme do nich za behu ukladať rôzne dáta. Vo funkcii print() je taktiež použité formátovanie reťazca pomocou špecifikácii formátu začínajúcich znakom „%”. V tomto prípade „%s“ očakáva reťazec, ktorý sa vyberie z premenných v zátvorke za vypisovaným reťazcom. Na výstupe z tohto skriptu nakoniec dostaneme reťazec:
Tento reťazec bol vytvorený v jazyku Python verzie 3.X.
V syntaxi jazyka Python je ešte veľa špecifickostí a odlišností od iných jazykov, ktoré neboli spomenuté. Pre viac informácií o syntaxi a možnostiach jazyka odporúčam preštudovať túto časť oficiálnej dokumentácie.
Zoznamy, polia, dáta a súbory
Hlavným významom vizualizácie je vyobrazenie väčšieho, či menšieho, množstva dát do podoby prínosnej pre ľudí. Veľkosť vizualizovaných dát sa zväčša ráta vo viac než stovkách či tisíckach hodnôt, ktoré vo väčšine prípadov je najprv potrebné spracovať do požadovanej podoby.
Začnime ale jednoducho. Jednou z najčastejšie používaných dátových štruktúr na reprezentáciu kolekcie dát je zoznam, ktorý sa v Pythone zapisuje v hranatých zátvorkách:
zoznam = [1, 2, 3, 4, 5]
print("zoznam =", zoznam)
Výstupom tohto skriptu je obsah zoznamu:
zoznam = [1, 2, 3, 4, 5]
Skúsme vypísať špecifickú hodnotu zo zoznamu:
i = 2
zoznam = [1, 2, 3, 4, 5]
print("zoznam[%d] = %d" % (i, zoznam[i]))
Skript vypíše hodnotu na 3 mieste, keďže pozície v zozname začínajú od nuly:
zoznam[2] = 3
Ak poznáme dĺžku zoznamu, jeho prvky môžeme priradiť do samostatných premenných:
zoznam = ["a", "b", "c"]
prvy, druhy, treti = zoznam
print("prvy = %s, druhy = %s, treti = %s" % (prvy, druhy, treti))
Výsledkom bude výpis:
prvy = a, druhy = b, treti = c
Python samozrejme ponúka mnohé ďalšie operácie, ktoré môžeme vykonať nad zoznamami, napríklad pridávanie hodnôt do už existujúceho zoznamu funkciou insert(), ako môžeme vidieť v tutoriále o dátových štruktúrach.
Avšak vo väčšine prípadov potrebujeme vybrať dáta z dátových súborov a pre také prípady je najvhodnejšie použiť Python knižnicu NumPy, ktorá nám umožňuje vyčítanie dát z dátových súborov, narábanie s viac-dimenzionálnymi poliami, vykonávanie matematických funkcií nad NumPy poliami a podobne. Taktiež je potrebné poznamenať fakt, že NumPy polia ponúkajú vyššiu efektívnosť pri práci s dátami ako aj menšiu spotrebu pamäte oproti bežnym Python listom. Pre ukážku tejto efektívnosti a podrobnejšie vysvetlenie rozdielov medzi nimi, odporúčam prečítať príkad zaoberajúci sa touto otázkou. Aj keď sa NumPy polia správajú podobne ako zoznamy o ktorých sme si práve povedali, nejedná sa o rovnaký dátový typ. Jednou z ich dodatočných vlastností, ktorú využijeme neskôr v príspevku, je možnosť vykonávať operácie ako násobenie a delenie, nad každým prvkom v poli. Pre viac informácií o schopnostiach NumPy knižnice si prezrite manuál NumPy.
Predtým než začneme načítavať dáta a vytvárať vizualizácie, skúsme najprv zapísať nami vytvorené dáta do súboru pomocou knižnice NumPy. Na začiatok si vytvoríme NumPy polia funkciou np.array() a následne tieto dve polia vložíme do nového poľa aby sme vytvorili dvojrozmerné pole. Funkciou np.savetxt() vytvoríme a uložíme do súboru „data.txt“ obsah poľa polí „data“, kde hodnoty každého poľa sa vypíšu do samostatných riadkov. Následne spätne vyčítame jednotlivé dáta z riadkov funkciou np.genfromtxt() do nových polí a vypíšeme ich.
# importuje knižnicu NumPy a skráti jej názov na "np"
import numpy as np
# vytvorí a naplní numpy polia dátami
M = np.array([1, 2, 3, 4, 5])
N = np.array([6, 7, 8, 9, 10])
# vytvorí a naplní numpy pole vytvorenými poliami
data = np.array([M, N])
file = "data.txt"
# funkcia vytvorí alebo prepíše súbor "data.txt" a vpíše doňho obsah poľa "data"
np.savetxt(file, data)
# funkcia vytiahne dáta zo súbora "data.txt" a uloží ich do nových polí M2 a N2
M2, N2 = np.genfromtxt(file)
# vypíše obsah oboch polí
print("M2 =", M2)
print("N2 =", N2)
M2 = [1, 2, 3, 4, 5]
N2 = [6, 7, 8, 9, 10]
Prešli sme si úplnými základmi práce s I/O a poliami, a teraz môžeme prejsť ku samotným vizualizáciám.
Vizualizačné schopnosti knižnice Matplotlib
Ako bolo spomenuté, knižnica Matplotlib je Python knižnica, ktorú budeme využívať na vizualizáciu dát do rôznych podôb. Či už diagramov, grafov alebo 3D zobrazení. Začneme od menej zložitých a pomaly sa prepracujeme až ku komplexnejším vizualizáciám, ktoré nám táto knižnica umožňuje vytvárať.
Čiarový diagram
Jedným z najzákladnejších diagramov je čiarový diagram skladajúci sa z X-ovej a Y-novej osi, a vykreslených súradnicových bodov. Tieto body sú následne prepojené čiarami v poradí v akom boli do diagramu pridané aby vytvárali čiarový diagram.
Najprv si vytvoríme dátový súbor s dátami, ktoré chceme vykresľovať. Pre tento príklad použijem dáta zo sčítaní obyvateľstva Slovenska od roku 1848 do roku 2011. V ďalších príkladoch už budem dáta z dátových súborov iba čítať.
import numpy as np
data1 = np.array([1848, 1869, 1880, 1890, 1900, 1910, 1921, 1930, 1946, 1950, 1961, 1970, 1980, 1991, 2001, 2011])
data2 = np.array([2442000, 2481811, 2477521, 2595180, 2782925, 2916657, 2993859, 3324111, 3327803, 3442317, 4174046, 4537290, 4991168, 5274335, 5379455, 5397036])
data = np.array([data1, data2])
np.savetxt("data.txt", data)
Z vytvoreného súboru „data.txt“ znova vytiahneme dáta, ktoré si uložíme do polí a vložíme ich do funkcie plt.plot(). Táto funkcia vezme dodané hodnoty a vykreslí jednotlivé body ako X/Y súradnice, ktoré následne prepojí podľa poradia v akom jej boli dodané. Predtým než sa pole s počtom obyvateľov vloží do funkcie, tak každá hodnota poľa bude predelená hodnotou „1,000,000“ aby sa zlepšila prehľadnosť diagramu.
Taktiež môžeme vykonať niekoľko štylistických úprav diagramu. Funkcia plt.grid(True) vykreslí mriežku pre zlepšenie prehľadnosti zobrazených dát. Funkcie plt.title(), plt.xlabel() a plt.ylabel() vykreslia textové popisy nad diagram a na obe osi. Nakoniec vyhotovený diagram uložíme ako súbor s názvom „ciarovy_diagram_1“ vo formáte PNG pomocou funkcie plt.savefig().
import matplotlib
matplotlib.use('Agg')
import numpy as np
import matplotlib.pyplot as plt
roky, populacia = np.genfromtxt("data.txt")
plt.plot(roky, populacia/1000000)
plt.grid(True)
plt.title("Vývoj obyvateľstva Slovenska od roku 1848 po 2011")
plt.xlabel("Rok sčítania")
plt.ylabel("Počet obyvateľov v miliónoch")
plt.savefig("ciarovy_diagram_1")
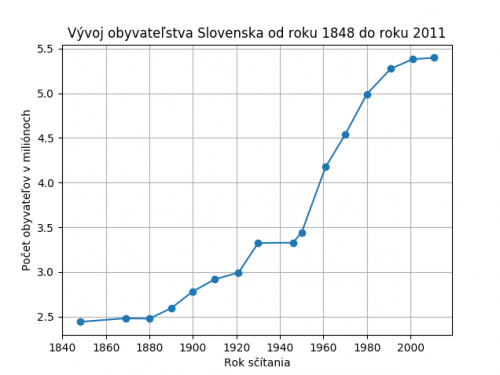
Samozrejme, samotný diagram nie je nutné zakaždým ukladať. Je možné ho totižto otvoriť v dočasnom okne. Ako ste si mohli všimnúť, medzi importy pribudol nový riadok matplotlib.use(‘Agg’), ktorého úlohou je prepínať takzvaný „backend“ knižnice. V režime „Agg“ je knižnica schopná výstup z kódu exportovať vo formáte PNG, ktorý je pre naše potreby postačujúci. Jednoducho povedané, „backend“ vykonáva všetku prácu na pozadí a určuje aké typy výstupov knižnica ponúka. Všetok kód ktorý sme doteraz napísali je iba „frontend“, ktorý „backend“ musí spracovať. Pre dodatočné informácie o “backend-och” odporúčam preštudovať zjednodušené oficiálne vysvetlenie z Matplotlib dokumentácie.
Pokiaľ však neprepneme mód „backend-u“, tak môžeme použiť funkciu plt.show(), ktorá nám vygeneruje výstup do dočasného okna.
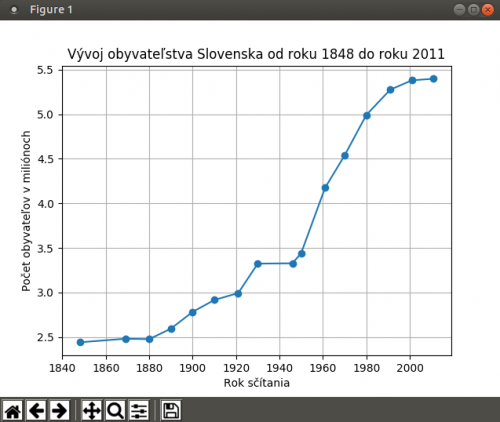
Samotný diagram je v tomto stave po dátovej stránke viacmenej prázdny, takže tam pridáme dodatočné dáta a upravíme diagram tak, aby jednotlivé vykreslené súradnicové body boli zvýraznené a pribudla legenda popisujúca jednotlivé dáta. To docielime pridaním argumentov marker a label.
Argument marker nastavuje typ symbolu aký bude vykreslený na jednotlivé body čiarového diagramu. Argument label priraďuje danej čiare popis, ktorý je použití v legende. Legenda diagramov je tvorená volaním funkcie plt.legend(), do ktorej v tomto prípade vkladáme argument loc s hodnotou „upper left“. Takýmto spôsobom vykreslíme legendu do ľavého horného rohu diagramu.
import matplotlib
matplotlib.use('Agg')
import numpy as np
import matplotlib.pyplot as plt
roky_SK, populacia_SK, roky_CZ, populacia_CZ, roky_HU, populacia_HU = np.genfromtxt("data.txt")
plt.plot(roky_SK, populacia_SK/1000000, marker="o", label="Slovensko")
plt.plot(roky_CZ, populacia_CZ/1000000, marker="o", label="Česko")
plt.plot(roky_HU, populacia_HU/1000000, marker="o", label="Maďarsko")
plt.grid(True)
plt.title("Vývoj obyvateľstva")
plt.xlabel("Rok sčítania")
plt.ylabel("Počet obyvateľov v miliónoch")
plt.legend(loc='upper left')
plt.savefig("ciarovy_diagram_2")
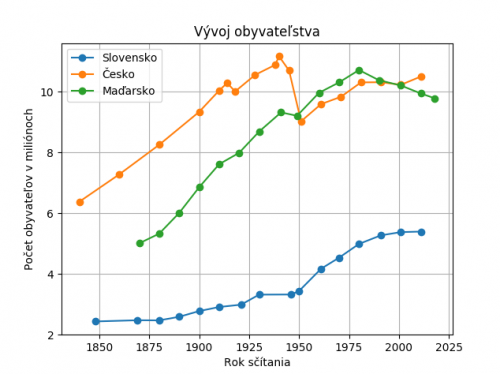
Histogram
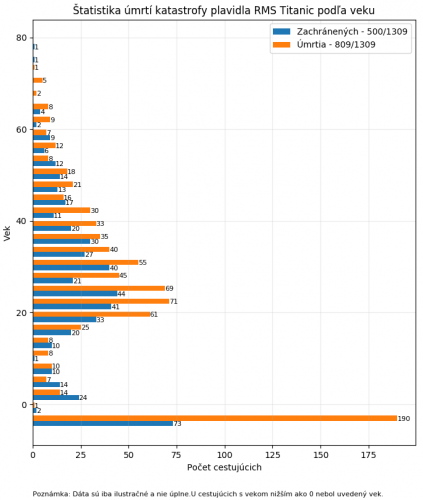
Histogram slúži na grafické zobrazenie frekvencií výskytu daných veličín. Histogramy sú vytvárané funkciou plt.hist(), ktorú použijeme v nasledujúcom príklade. Tentokrát budeme vykresľovať dáta o pasažieroch lode RMS Titanic, ktoré boli získané z voľne dostupného repozitára dátových balíčkov.
Získané dáta sú vo formáte CSV, v ktorom sú uložené po stĺpcoch, takže budeme z nimi pracovať inak ako doteraz. Do NumPy funkcie np.genfromtxt() pribudli argumenty delimiter, ktorý určuje aký znak slúži ako rozdeľovač dát v súbore, a argument names, ktorý v stave True automaticky pomenuje všetky dáta z každého stĺpca podľa reťazcov v prvom riadku súboru. Premenná „data“ neobsahuje iba jednu sadu hodnôt, ako tomu bolo v minulom príklade, ale všetky dáta zo súbora. Pre naše potreby nám však stačí stĺpec „survived“, popisujúci či daný pasažier prežil, a stĺpec „age“, ktorý obsahuje vek pasažiera. Ak chceme získať vek všetkých pasažierov, tak namiesto indexu použijeme meno požadovaného stĺpca, tj. data[“age”].
Po spracovaní dát vytvoríme prostredie do ktorého budeme dáta vykresľovať použitím funkcie plt.figure() s argumentom figsize=(8,16), ktorá vytvorí prostredie o veľkosti 800x1600 pixlov. Funkcia plt.hist(), ktorá vykreslí histogram, dostane na vstupe dvojicu polí, „data[data[‘survived’]==1][‘age’]“ a „data[data[‘survived’]==0][‘age’]“, ktoré rozdeľujú dáta o pasažieroch podľa toho či katastrofu prežili alebo nie. Vnútro prvej zátvorky v oboch dvojiciach, data[‘survived’]==X, slúži ako pravdivostná hodnota, ktorá vráti iba dáta z oboch stĺpcov kde hodnota „survived“ je 1 alebo 0. Tým docielime, že histogram bude obsahovať dvojice stĺpcov aby sme dokázali jednoduchšie vidieť distribúciu dát v diagrame. V argumente label vytvárame reťazce popisujúce vykreslené stĺpce histogramu, ktoré sa budú nachádzať v legende. Argumentom orientation povieme knižnici aby vykreslila histogram horizontálne, nie vertikálne, a argument bins nastaví počet stĺpcov medzi ktoré má knižnica rozložiť vykresľované dáta.
import matplotlib
matplotlib.use('Agg')
import numpy as np
import matplotlib.pyplot as plt
data = np.genfromtxt('TitanicSurvival.csv', delimiter=',', names=True)
plt.figure(figsize=(8,16))
plt.hist([data[data['survived']==1]['age'], data[data['survived']==0]['age']],
label=['Zachránených - %s/%s' % (len(data[data['survived']==1]),
len(data['survived'])),
'Úmrtia - %s/%s' % (len(data[data['survived']==0]),
len(data['survived']))],
orientation="horizontal", bins=30)
plt.grid(True, alpha=0.25)
plt.title("Štatistika úmrtí katastrofy plavidla RMS Titanic podľa veku")
plt.xlabel("Počet cestujúcich")
plt.ylabel("Vek")
plt.legend()
plt.text(0, -20, "Poznámka: Dáta sú iba ilustračné a nie úplne."
"U cestujúcich s vekom nižším ako 0 nebol uvedený vek.",
fontsize=8)
plt.savefig("titanic_histogram_test")
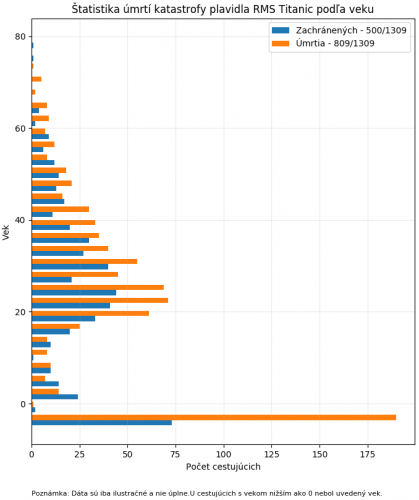
Histogram môžeme zdokonaliť pridaním presných hodnôt nad jednotlivé stĺpce histogramu. To docielime cyklom ktorý bude prechádzať cez všetky vykreslené stĺpce plt.gca().patches. Pokiaľ šírka daného stĺpca v cykle, i.get_width(), je väčšia ako 0, tak na hodnote šírky stĺpca (hodnota X) a pozícií Y, i.get_y(), vypíšeme hodnotu i.get_width(), tj. počet pasažierov daného stĺpca. Argumentom fontsize už iba špecifikujeme veľkosť písma, ktorá nespôsobí pretínanie textov.
import matplotlib
matplotlib.use('Agg')
import numpy as np
import matplotlib.pyplot as plt
data = np.genfromtxt('TitanicSurvival.csv', delimiter=',', names=True)
plt.figure(figsize=(8,16))
plt.hist([data[data['survived']==1]['age'], data[data['survived']==0]['age']],
label=['Zachránených - %s/%s' % (len(data[data['survived']==1]),
len(data['survived'])),
'Úmrtia - %s/%s' % (len(data[data['survived']==0]),
len(data['survived']))],
orientation="horizontal", bins=30)
for i in plt.gca().patches:
if i.get_width() > 0:
plt.gca().text(i.get_width(), i.get_y(), int(i.get_width()), fontsize=8)
plt.grid(True, alpha=0.25)
plt.title("Štatistika úmrtí katastrofy plavidla RMS Titanic podľa veku")
plt.xlabel("Počet cestujúcich")
plt.ylabel("Vek")
plt.legend()
plt.text(0, -20, "Poznámka: Dáta sú iba ilustračné a nie úplne."
"U cestujúcich s vekom nižším ako 0 nebol uvedený vek.",
fontsize=8)
plt.savefig("titanic_histogram")
Vizualizácia dát na projekciu Zeme knižnice Matplotlib Basemap
Niekedy je namerané alebo simulované dáta lepšie vizualizovať v inej forme než len vo forme čiar, stĺpcov alebo hodnôt. Teplota vzduchu, zrážky, tlak, žiarenie a podobne, sú niekedy vizualizované aj na projekciách celej Zeme alebo na jej špecifických častiach. Knižnica Matplotlib Basemap rozširuje funkcionalitu knižnice o väčšinu typov projekcií Zeme. Na nižšie uvedenom príklade si ukážeme vykreslenie teplotných dát nameraných organizáciou Earth System Research Laboratory získaných z ich dátového repozitára.
Táto organizácia ponúka množstvo klimatických dát, hlavne vo formáte dátových balíčkov .nc, NetCDF (po anglicky, Network Common Data Form), na ktorých spracovanie je potrebné importovať novú knižnicu netCDF4. Po načítaní dátového súbora „air.sig995.2016.nc“, vytiahneme jednotlivé dáta a uložíme ich do polí air - teplotné dáta, lat - zemepisná šírka, a lon - zemepisná dĺžka. Teplotné dáta sú avšak v jednotkách Kelvin a nie Celzius, takže od každej hodnoty musíme odčítať hodnotu 273.15 aby sme dostali dáta požadovaného formátu.
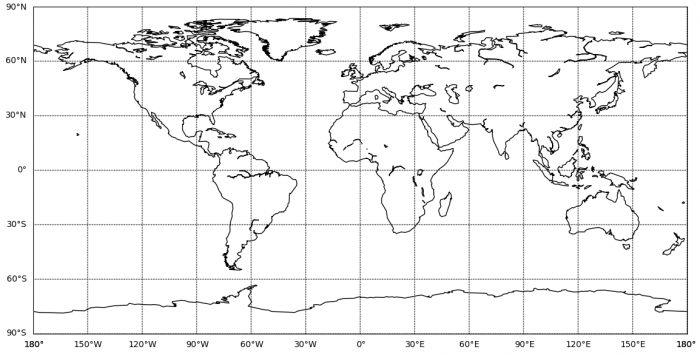
Vytvoríme samotný diagram, ktorému nastavíme požadovanú veľkosť argumentom figsize=(15,7), ktorý vytvorí na výstupe obrazec o veľkosti 1500x700 pixlov. Po vytvorený prostredia, pristúpime ku použitiu knižnice Basemap, kde pomocou funkcie Basemap() vytvoríme požadovanú projekciu mapy Zeme. V tomto prípade ide o bežnú ekvidistantnú valcovú projekciu ako nám jej argument, projection=“cyl”, napovedá. V nasledujúcich krokoch vypíšeme na osiach hodnoty zemepisnej šírky a dĺžky funkciami m.drawparallels(), a m.drawmeridians() respektívne. Obe funkcie obsahujú dva argumenty, kde v prvom voláme NumPy funkciu np.arrange(), ktorá nám vracia rovnomerne rozdelené pole hodnôt medzi prvými dvoma hodnotami, a v argumente labels špecifikujme na ktorých stranách projekcie chcem dané osi vykresliť. V tomto prípade nám labels=[True, False, False, False] vykreslia dáta iba na ľavej strane, keďže štyri pravdivostné hodnoty v argumente zodpovedajú ľavej, pravej, hornej a spodnej osi v tomto poradí. Poslednou Basemap funkciou je m.drawcoastlines(), ktorá vykreslí celkové pobrežie pevnín.
import matplotlib
matplotlib.use('Agg')
import netCDF4
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
f = netCDF4.Dataset("air.sig995.2016.nc")
air = f.variables["air"]
air_c = air[:] - 273.15
lat = f.variables["lat"]
lon = f.variables["lon"]
plt.figure(figsize=(15, 7))
m = Basemap(projection="cyl")
m.drawparallels(np.arange(-90., 91., 30.), labels=[True, False, False, False])
m.drawmeridians(np.arange(0., 351., 30.), labels=[False, False, False, True])
m.drawcoastlines()
plt.savefig("projekcia_zeme")
Takto vyzerá nami vykreslená projekcia bez akejkoľvek aplikácie nameraných dát:
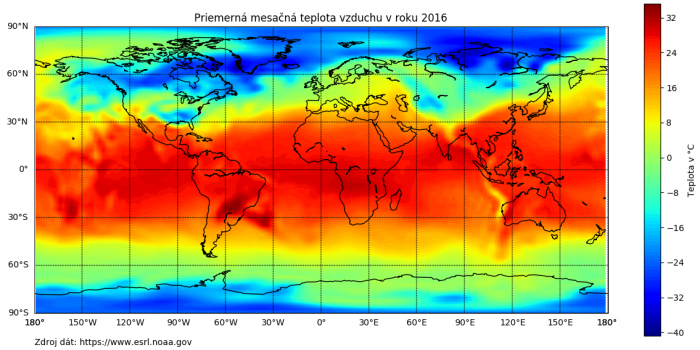
Predtým než ale môžeme samotné hodnoty vykresliť je ich nutné ešte upraviť do formátu v akom ich Matplotlib dokáže spracovať. Hodnoty polí lon a lat vložíme do NumPy funkcie np.meshgrid(), kde na jej výstupe dostaneme dvojicu súradnicové polí, kde každá dvojica z oboch polí popisuje každý jeden bod na projekcii. Tieto polia si uložíme ako polia x a y. Následne už len ostáva vložiť súradnicové polia x a y, a teplotné dáta air_c do funkcie m.contourf(). Od každej hodnoty poľa x je vo funkcii odrátaná hodnota „179“ a to z toho dôvodu, že namerané dáta majú hodnoty x v rozsahu 0 až 359 ale naša projekcia má zemepisnú šírku v rozsahu -180 až 180. Štvrtý argument, hodnota „100“, nastavuje počet úrovní medzi ktoré sa majú teplotné dáta roztiahnuť, tj. aké široké je farebné spektrum s ktorým funkcia môže pracovať. Piaty argument, cmap, nastavujeme požadovanú farebnú škálu z mnohých, ktorá má byť použitá pri vykresľovaní dát. K samotnej projekcii samozrejme potrebujeme hodnotový stĺpec s jednotlivými hodnotami, ktoré farebná škála predstavuje. Ten je vytvorený funkciou plt.colorbar() s argumentom label, ktorý zabezpečí vypísanie popisu stĺpca.
Posledným krokom je už len vypísanie popisu diagramu a uvedeniu zdroja funkciou plt.text(), ktorá nám umožňuje vypísanie akéhokoľvek textu kdekoľvek vo vizualizácií. Prvé dva argumenty predstavujú X-ovú a Y-novú súradnicu a tretí prestavuje reťazec na vypísanie.
import matplotlib
matplotlib.use('Agg')
import netCDF4
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
f = netCDF4.Dataset("air.sig995.2016.nc")
air = f.variables["air"]
air_c = air[:] - 273.15
lat = f.variables["lat"]
lon = f.variables["lon"]
plt.figure(figsize=(15, 7))
m = Basemap(projection="cyl")
m.drawparallels(np.arange(-90., 91., 30.), labels=[True, False, False, False])
m.drawmeridians(np.arange(0., 351., 30.), labels=[False, False, False, True])
m.drawcoastlines()
x, y = np.meshgrid(lon, lat)
m.contourf(x-179, y, air_c[0,:,:], 100, cmap=plt.cm.get_cmap("jet"))
plt.colorbar(label="Teplota v °C")
plt.title("Priemerná mesačná teplota vzduchu v roku 2016")
plt.text(-180, -110, "Zdroj dát: https://www.esrl.noaa.gov")
plt.savefig("priemerna_mesacna_teplota")
Takto vyzerá finálny výstup z nameraných teplotných dát popisujúcich priemer mesačných teplôt vzduchu na celej Zemi za rok 2016.
Vykreslenie dát v 3D prostredí
Pôvodne bola knižnica Matplotlib zameraná a schopná vykresľovať iba dvoj-dimenzionálne vizualizácie, ale vo vývoji neskôr pribudol dodatočný toolkit, mplot3d, ktorý umožňuje vykresľovanie dát do tretej dimenzie. Jednou z výhod je interaktivita takejto vizualizácia, tj. možnosť otáčať a pozorovať vykreslený objekt z akéhokoľvek smeru.
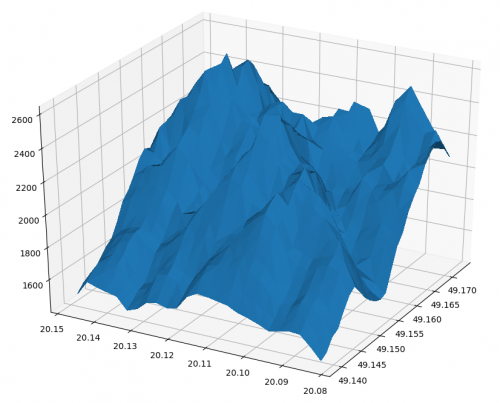
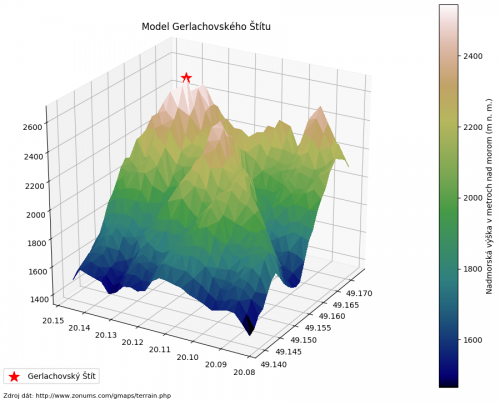
Tvorba takejto vizualizácie nie je o nič viac zložitá ako vykresľovanie dát do dvojrozmerného prostredia. Okrem nutnosti importovania samotného toolkitu, „from mpl_toolkits.mplot3d import Axes3D“, 3D vizualizácia potrebuje okrem dát pre rozmery X a Y, aj rozmer Z. V tomto príklade vykreslíme model Gerlachovského Štítu z dát získaných pomocou GPS, ktoré obsahujú zemepisnú šírku, dĺžku a nadmorskú výšku. Funkciou plt.figure(figsize=(12,12)) vytvoríme prostredie o veľkosti 1200x1200 pixlov a uložíme si jeho referenciu do premennej fig. Z nej následne získame inštancie všetkých osí a uložíme ich do premennej ax. Inštancie získame funkciou gca(), ktorú voláme nad nami vytvorenou referenciou prostredia fig, a nastavíme ich na 3D projekciu argumentom projection=“3d”.
Nad získanou inštanciou 3D osí, ax, zavoláme vizualizačnú funkciu ax.plot_trisurf(), ktorá dostane na vstupe polia obsahujúce hodnoty zemepisnej šírky a dĺžky, a nadmorskej výšky. Dodatočným argumentom je argument antialiased, ktorý nastavíme na False, keďže v stave True by hrany vizualizácie boli zvýraznené, čo v tomto prípade nie je žiadané.
import matplotlib
matplotlib.use('Agg')
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
lat = np.genfromtxt("gerlach_data", skip_header=1, usecols=0)
lon = np.genfromtxt("gerlach_data", skip_header=1, usecols=1)
z = np.genfromtxt("gerlach_data", skip_header=1, usecols=2)
fig = plt.figure(figsize=(12,12))
ax = fig.gca(projection="3d")
ax.plot_trisurf(lat, lon, z, antialiased=False)
plt.savefig("gerlachovsky_stit_test")
Ako tomu bolo pri ostatných príkladoch, je nutné urobiť dodatočné úpravy. Samotná 3D vizualizácia vyžaduje farebnú škálu, ktorá by vizuálne zvýraznila výškové rozdiely medzi jednotlivými časťami. To docielime importovaním Matplotlib modulu cm, „from matplotlib import cm“, ktorá slúži na prácu s farebnými škálami, a pridaním argumentu cmap=cm.gist_earth do funkciu ax.plot_trisurf(). Farebná škála gist_earth je vhodná pri takýchto topografických vizualizáciách, keďže využíva prirodzenú škálu bežne známu z máp. Avšak aby sme boli schopní neskôr vykresliť farebnú škálu vizualizácie, musíme získané dáta o vytvorenej 3D vizualizácií uložiť do premennej, ktorú nazveme surface.
Taktiež označíme vrchol Gerlach funkciou ax.scatter(), ktorej dodáme súradnice najvyššej hodnoty nadmorskej výšky. Použitý symbol bude červená hviezda ako vyplýva z argumentov marker="*" a color=“red”. Argument s nastaví rozmer symbolu vo vizualizácií a label vytvorí popis pre daný symbol, ktorý bude viditeľný v legende, plt.legend(loc=“lower left”), ktorá sa bude nachádzať v ľavom dolnom rohu.
Následne vykreslíme farebnú škálu funkciou plt.colorbar(), ktorej dodáme výstup z funkcie ax.plot_trisurf(), premennú surface, obsahujúcu dáta o vytvorenej 3D vizualizácií a popise škály. Proces ukončíme vypísaním nadpisu funkciou plt.title() a použitého zdroja funkciou ax.text2D(), ktorá funguje rovnako ako funkcia plt.text() používaná v predchádzajúcich príkladoch.
Ako ste si ale mohli všimnúť, funkcia plot_trisurf() je volaná nad objektom obsahujúcim inštanciu osí vizualizácie, ax. Všetky Matplotlib funkcie, okrem funkcií z knižnice Basemap, použité doposiaľ pochádzali z modulu pyplot, ktorý obsahuje funkcie na manipuláciu samotného prostredia vizualizácie (plt.figure(), plt.colorbar() a pod.). Avšak na vizualizáciu do 3D prostredia nie je postačujúce mať informácie iba o samotnom prostredí, ale je nutné pracovať nad inštanciou všetkých troch osí, aby bolo možné dáta vykresliť do 3D prostredia. Z toho dôvodu je nutné získať inštanciu osí funkciou gca() a až nad ňou môžeme vykonať funkciu plot_trisurf().
import matplotlib
matplotlib.use('Agg')
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
lat = np.genfromtxt("gerlach_data", skip_header=1, usecols=0)
lon = np.genfromtxt("gerlach_data", skip_header=1, usecols=1)
z = np.genfromtxt("gerlach_data", skip_header=1, usecols=2)
fig = plt.figure(figsize=(12,12))
ax = fig.gca(projection="3d")
surface = ax.plot_trisurf(lat, lon, z, cmap=cm.gist_earth, antialiased=False)
i = list(z).index(max(z))
ax.scatter(lat[i], lon[i], max(z), marker="*", color="red",
s=200, label="Gerlachovský Štít")
plt.colorbar(surface, label="Nadmorská výška v metroch nad morom (m n. m.)")
plt.title("Model Gerlachovského Štítu")
plt.legend(loc="lower left")
ax.text2D(-0.09325, -0.1,
"Zdroj dát: http://www.zonums.com/gmaps/terrain.php", fontsize=8)
plt.savefig("gerlachovsky_stit")
Záver
V tomto príspevku som iba načal malú časť vizualizačných schopností knižnice Matplotlib a jej toolkit-ov. Možností úprav a spôsobov ktorými je možné špecifikovať vizualizačný proces je vážne mnoho. Komukoľvek kto má záujem o vizualizáciu dát vrelo odporúčam aby sám otestoval možnosti knižnice Matplotlib v spolupráci s knižnicou NumPy, keďže spoločne predstavujú skutočne mocný nástroj na efektívnu a rýchlu tvorbu vizualizácií.