Umelej inteligencii (AI — artifical inteligence) je medzi informatikmi každým rokom venovaná väčšia pozornosť. Možno ste počuli o projekte AlphaGo od Deepmind Technologies, ktorý sa v roku 2017 stal najlepším hráčom 3000 rokov starej čínskej hry Go. V OpenAI dokázali vytvoriť hráča OpenAI 5 pre online počítačovú hru Dota 2, ktorý v apríli 2019 porazil majstra sveta v plnej hre 5 proti 5. Podobných príkladov je každým rokom viac a viac a majú spoločné to, že sa to všetko naučili sami od úplnej nuly. V tomto návode si ukážeme jeden zo základných algoritmov strojového učenia s posilňovaním — Q-learning v Pythone na niektorých jednoduchých prostrediach v Gym od OpenAI.

Učenie s posilňovaním
Práve ste si kúpili psa. Ten ale vôbec nerozumie vašim slovám. Čo urobíte? Vezmete niečo, čomu rozumie, napríklad jedlo. Neustále opakujete príkazy a keď urobí to, čo od neho očakávate, dostane od vás lahodnú odmenu. V mozgu vášho psa sa práve posilňujú logické spojenia medzi príkazom a akciou, ktorú je potrebné vykonať, aby bola dosiahnutá odmena. Opakovaním tohto procesu si môžete vychovať spoľahlivého spoločníka.
V informatike sa tento spôsob učenia nazýva učenie s posilňovaním (RL — reinforcement learning). RL rieši problém výberu čo najlepšej akcie v danom stave pre dosiahnutie čo najväčšej odmeny v budúcnosti. Pre lepšie porozumenie je potrebné zadefinovať si niekoľko základných pojmov:
- Agent — entita, ktorá rieši problém v danom prostredí. Vykonáva akciu na základe stavu v ktorom sa aktuálne nachádza.
- Prostredie (environment) — prostredie v ktorom agent rieši problém. Napríklad šachovnica alebo počítačová hra.
- Stav (state/observation) — konkrétny stav prostredia, napríklad pozícia agenta, jeho rýchlosť, pozícia nepriateľa.
- Akcia (action) — akcia, ktorú môže agent v danom prostredí a stave vykonať, napríklad „choď doprava“ alebo „vystreľ na nepriateľa“. Po vykonaní akcie agent prechádza do ďalšieho stavu.
- Odmena (reward) — odmena, ktorú agent dostane po vykonaní akcie v novom stave, napríklad nájdenie pokladnice, alebo príchod do cieľa. Pri negatívnych hodnotách, napríklad pri spadnutí do diery alebo strate života, sa môže označovať tiež ako penalizácia (penalty).
- Stratégia (policy) — pravidlá, podľa ktorých sa agent snaží vybrať čo najlepšiu akciu pre dosiahnutie čo najvyššej odmeny.
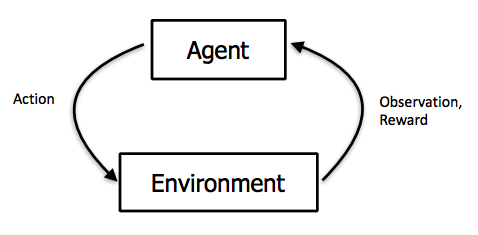
Proces učenia sa je možné v jednoduchosti opísať nasledovne:
- Prezretie prostredia v aktuálnom stave
- Výber a vykonanie ďalšej akcie použitím stratégie
- Získanie odmeny alebo penalizácie za prechod do nového stavu
- Učenie sa zo skúseností a úprava stratégie
- Opakovanie tohto procesu pokiaľ sa nevytvorí optimálna stratégia
Q-learning algoritmus
Jeden z najjednoduchších algoritmov RL je Q-learning. Je vhodný pre riešenie jednoduchých problémov, pri ktorých môžeme vyjadriť stav prostredia aj všetky akcie v diskrétnej forme — konečnej množine. Agent si vždy vyberá akciu na základe tabuľky — Q-table. Tabuľka obsahuje hodnotu kvality každej možnej akcie v každom stave, v ktorom sa môže agent ocitnúť, čiže ktorá akcia v danom stave bude viesť k získaniu čo najväčšej celkovej odmeny.
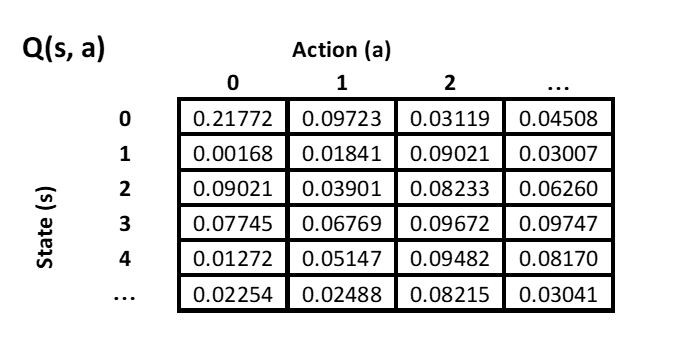
Na príklade tabuľky vyššie môžeme vidieť zoznam všetkých akcií, ktoré môže agent vykonať na osi X. Na osi Y je zoznam všetkých možných stavov prostredia. Agent si prezrie hodnoty pre všetky akcie v aktuálnom stave a vyberie tú, ktorá predpokladá najvyššiu celkovú odmenu, čiže ak sa ocitne v stave 4, vyberie si akciu 2. Samozrejme, pre človeka vytvoriť takúto tabuľku ručne by bolo veľmi náročné až nemožné. Naším cieľom je, aby sa agent tieto hodnoty dokázal naučiť sám bez toho, aby vedel, čo samotné akcie a stavy predstavujú.
Exploration vs. exploitation
Na začiatku trénovania vytvoríme agentovi tabuľku, kde inicializujeme všetky hodnoty na 0. Preto musí agent na začiatku prostredie preskúmať výberom náhodných akcií (exploration). Ak ho niektorá z akcií privedie k odmene, aktualizujeme tabuľku pre danú akciu vykonanú z predošlého stavu pomocou tejto hodnoty. Na základe toho, môže agent postupne vyberať akcie, ktoré ho zaručene privedú k odmene (exploitation). Avšak, ak by sme po nájdení prvého riešenia problému začali vždy vyberať len tie najlepšie akcie podľa aktuálnej tabuľky, nemusela by byť táto cesta aj najoptimálnejšia, pretože agent nestihol preskúmať všetky možné riešenia. Preto je vhodné počas tréningu ponechať agentovi šancu vykonať náhodnú akciu namiesto tej najlepšej v tabuľke. Na to nám slúži premenná ε (“epsilon”) určujúca percentuálnu šancu, že si agent vyberie náhodnú akciu. Túto hodnotu zvykneme na začiatku nastaviť vyššiu a postupne ju znižovať.
Aktualizácia tabuľky
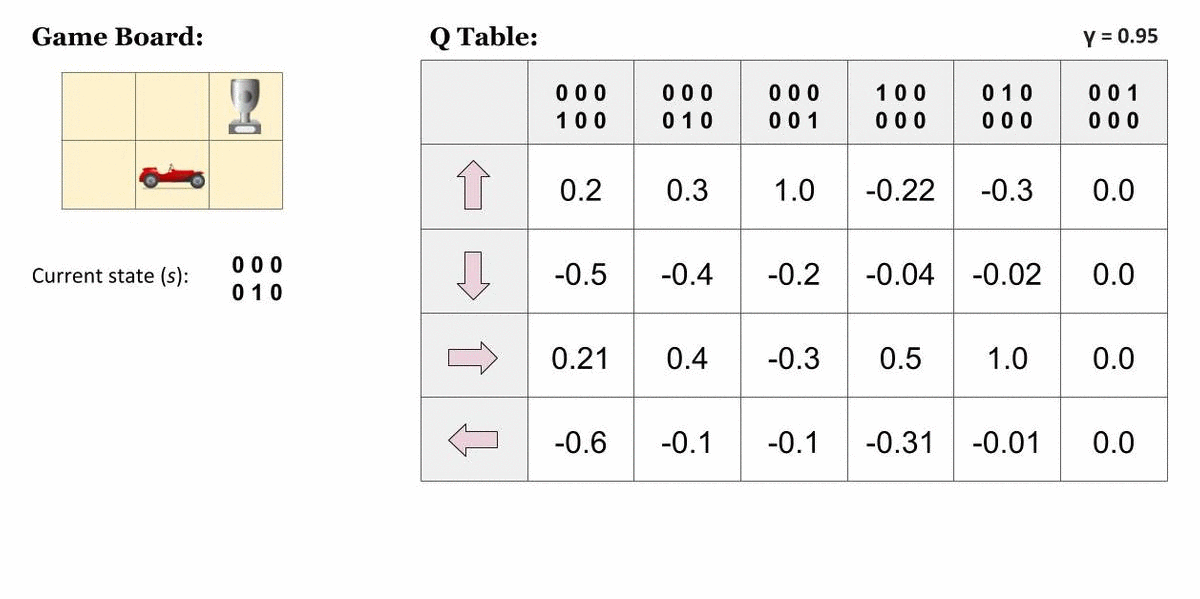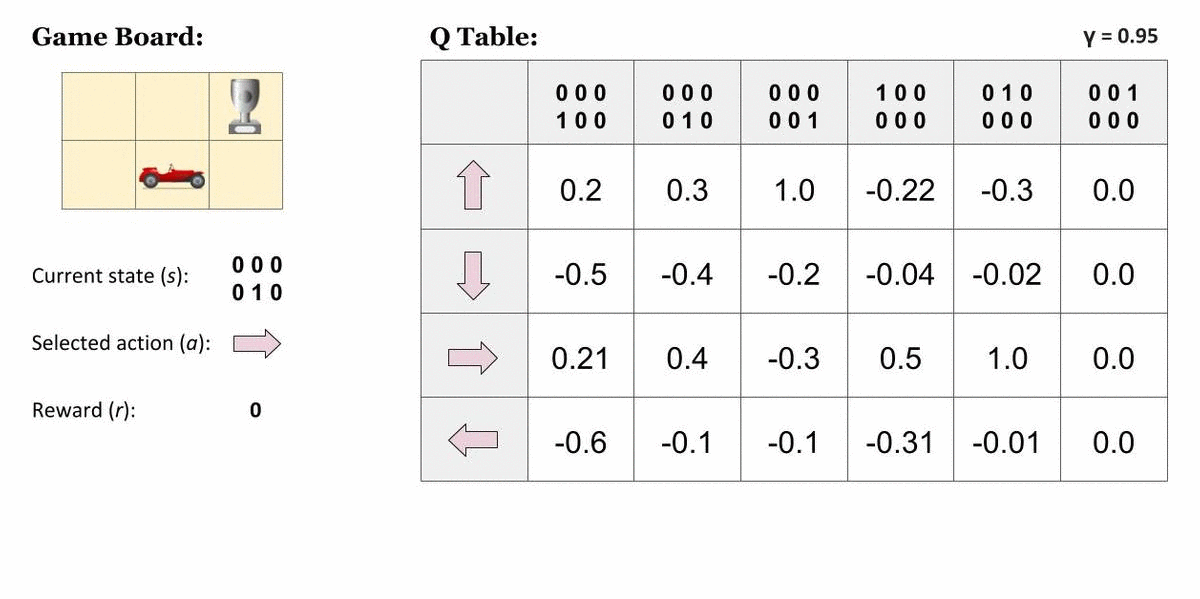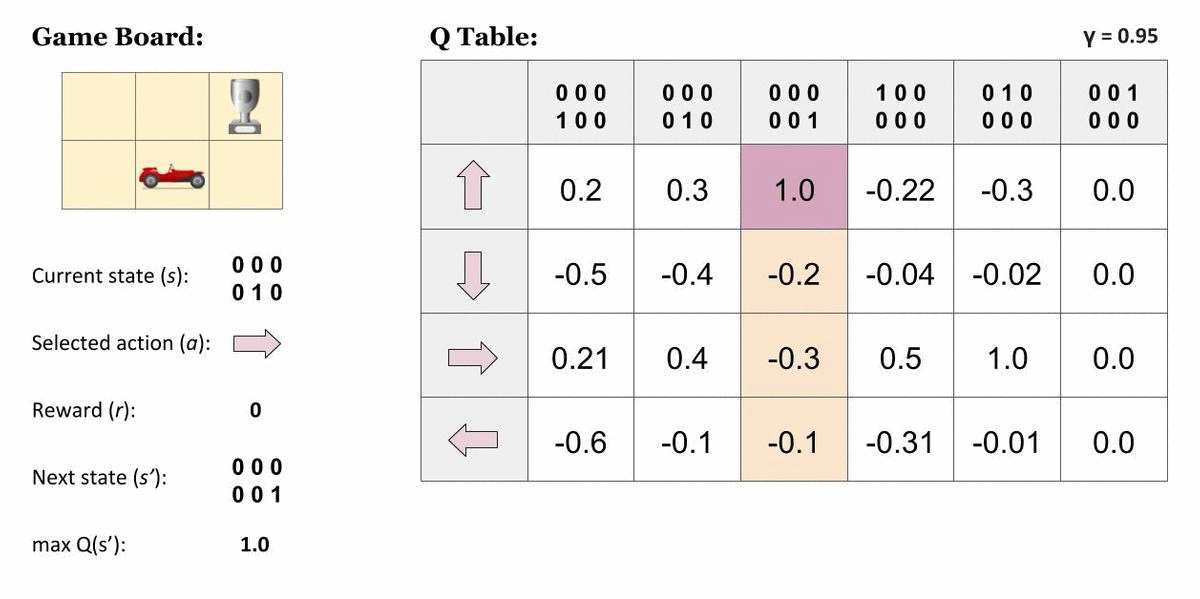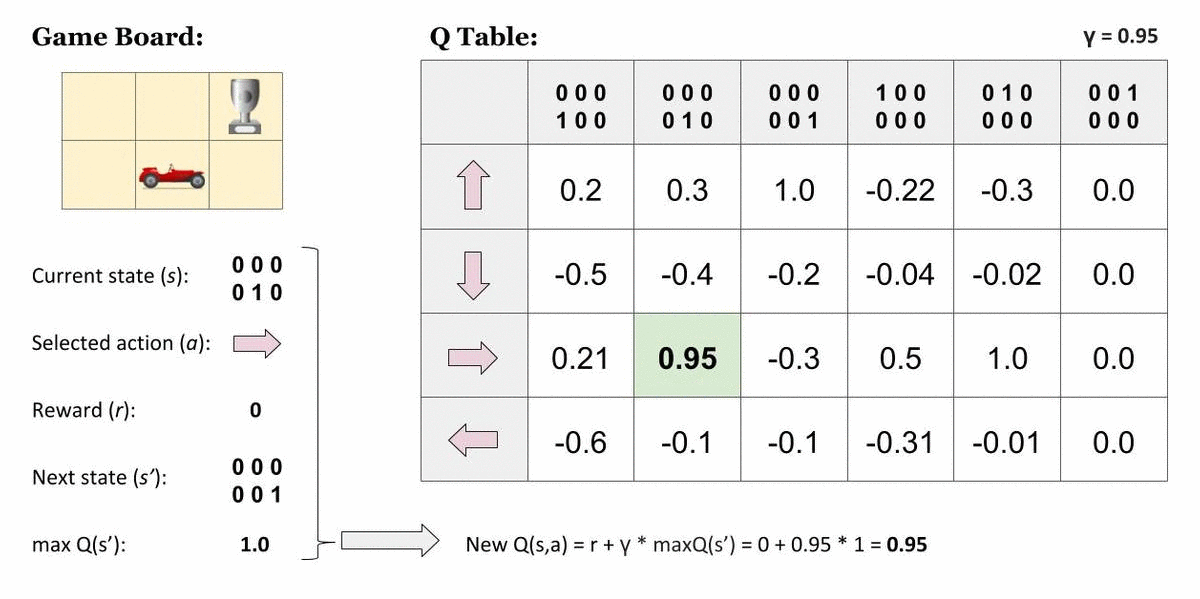
Tabuľku aktualizujeme po každom vykonaní akcie a zmene stavu. Ocitáme sa v novom stave, no aktualizujeme hodnotu prislúchajúcu starému stavu a akcie, ktorú sme vykonali. Použijeme na to nasledujúci vzorec:

- Q (st, at) — hodnota v tabuľke pre vykonanie akcie at v starom stave st
- Q new — nová vypočítaná hodnota, ktorou nahradíme starú hodnotu Q(st, at)
- max Q(st+1, a) — najvyššia hodnota v tabuľke v novom stave st + 1
- α („alfa“) — intenzita učenia — 0 < α ≤ 1 — určuje, do akej miery sa stará hodnota nahradí novou. Zvykne sa určiť konštantná hodnota, napr. α = 0,1.
- rt — odmena získana za prechod do nového stavu
- γ („gamma“) — faktor „zľavy“ — 0 < γ ≤ 1 — určuje dôležitosť celkových odmien dosiahnutých v budúcnosti. Pri hodnote 0 sa stane agent krátkozrakým — bude brať do úvahy len aktuálne získanú odmenu, bez ohľadu na budúce odmeny. Optimálna hodnota zvykne byť medzi 0,9 a 0,99. Dôsledkom je, že možná odmena v budúcnosti pomaly stráca význam, čím dlhšie k nej trvá cesta z aktuálneho stavu.
Implementácia Q-learning
Implementáciu si znázorníme v jazyku Python a budeme ju demonštrovať na niektorých prostrediach v knižnici Gym. Gym obsahuje prostredia rôznych klasických problémov RL, čím nám umožní zamerať sa na samotný algoritmus, namiesto vytvárania vlastných prostredí.
Príprava prostredia
Na začiatok je potrebné stiahnuť knižnicu gym s prostrediami a knižnicu numpy pre prácu so samotnou tabuľkou. To môžeme urobiť pomocou nástroja pip:
$ pip install gym
$ pip install numpy
a následne ich importujeme
import gym
import numpy as np
Zvolíme si prostredie, s ktorým chceme pracovať. V prvom príklade to bude „Taxi-v3“. Cieľom je, aby agent — taxík — vyzdvihol pasažiera a vysadil ho na inom určenom mieste. Prostredím je parkovisko tvorené mriežkou 5×5. Preto sa taxík môže nachádzať v 25 rôznych stavoch. Pasažier môže byť v 5 rôznych stavoch — na jednom zo 4 určených miest (R, G, Y, B), alebo v taxíku. Destinácia pasažiera môže byť na jednom zo 4 miest (R, G, Y, B). Celkový počet rôznych stavov je preto 5×5×5×4 = 500.
Taxík môže vykonať jednu zo 6 akcií: ísť hore, dole, vpravo, vľavo, vyzdvihnúť pasažiera a vyložiť pasažiera. Preto bude mať naša tabuľka rozmery 6 × 500 = 3000. V prostredí sa tiež nachádzajú steny, cez ktoré taxík nesmie prechádzať.
Agent vyhráva, keď úspešne vysadí pasažiera v jeho destinácií a dostáva odmenu +20. Po každom ťahu, v ktorom agent ešte nevysadil pasažiera na správnom mieste, dostáva agent penalizáciu -1. Pri nesprávnom použití akcie vyzdvihnutia alebo vyloženia, dostáva penalizáciu -10.
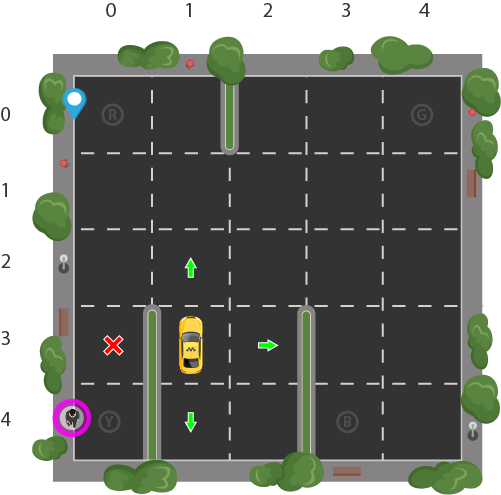
Všetky spomenuté pravidlá a funkcionalita prostredia sú už implementované v knižnici gym. Nastavené hodnoty odmien a penalizácií majú pomôcť agentovi hľadať čo najrýchlejší spôsob prepravy pasažiera na správne miesto. Nie je vždy potrebné, aby sme úplne rozumeli celému prostrediu, keďže agent na to musí prísť aj tak sám. Našou jedinou úlohou je implementovať spôsob vyberania akcie v každom kroku.
Načítame prostredie a uložíme do premennej
env = gym.make("Taxi-v3")
Každé prostredie má atribúty observation_space — údaj o type a veľkosti dát opisujúcich dané prostredie, a action_space — údaj o type a množstve akcií ktoré môže agent v danom prostredí vykonať. Najčastejšie sú typu Discrete alebo Box.
Discrete označuje diskrétnu, konečnú množinu všetkých možných stavov alebo akcií. Ak sa observation_space rovná Discrete(10), znamená to, že agent sa môže v danom prostredí ocitnúť v 10 rôznych stavoch (od 0 po 9). Rovnako pre action_space by to znamenalo, že môže vykonať 10 rôznych akcií.
Box označuje množinu kontiunálnych hodnôt v istom rozmedzí. To znamená, ak by bol observation_space — Box(4,) — atribútmi prostredia sú 4 rôzne reálne čísla ako napríklad pozícia, rýchlosť a podobne. Minimum a maximum pre každý z týchto atribútov môžeme získať pomocou atribútov observation_space.high (zoznam horných ohraničení) a observation_space.low (zoznam dolných ohraničení). Keďže vytvorenie tabuľky pre Q-learning si vyžaduje diskrétne hodnoty, musíme pre prostredia s observation_space typu Box všetky hodnoty vhodne diskretizovať.
Môžeme si vypísať typ observation_space a action_space pre naše prstredie Taxi:
>>> env.observation_space
Discrete(500)
>>> env.action_space
Discrete(6)
Môžeme vidieť, že prostredie má naozaj 500 rôznych stavov a 6 akcií.
Ďalej si vytvoríme našu Q tabuľku. Keďže chceme vytvoriť kód funkčný aj pre iné prostredia a nemôžeme pracovať s typom Discrete a Box rovnako, overíme si najprv ich typy a uložíme veľkosti.
# Naimportujeme si jednotlivé typy pre jednoduchšie overovanie
from gym.spaces import Box, Discrete
if isinstance(env.observation_space, Discrete):
# Získanie veľkosti observation_space
OS_SIZE = [env.observation_space.n]
if isinstance(env.action_space, Discrete):
# Získanie veľkosti action_space
AS_SIZE = [env.action_space.n]
# Vytvoríme tabuľku a naplníme ju nulami
q_table = np.full((OS_SIZE + AS_SIZE), 0.0)
Učenie
Samotné učenie prebieha v epizódach. Epizóda je akoby jedným herným kolom, ktoré končí po dosiahnutí terminálneho stavu. To môže byť dosiahnutie cieľa alebo prísť o všetky životy a pod. Epizódu môžeme ukončiť aj po dosiahnutí limitu maximálneho počtu krokov. Za jeden krok sa považuje vykonanie akcie a následná zmena stavu. V prípade nášho taxíka je konečným stavom vysadenie pasažiera na správnom mieste. Maximálny počet krokov pre dosiahnutie tohto cieľa je 200.
Znázorniť celý cyklus učenia sa, zatiaľ len s použitím náhodných akcií, môžeme takto:
# Metóda na pretypovanie stavu na tuple pre ľahšiu prácu s tabuľkou neskôr
def get_state(state):
if isinstance(env.observation_space, Discrete):
return (state,)
EPISODES = 2000 # Počet epizód, ktoré chceme vykonať
SHOW_EVERY = 400 # Po koľkých epizódach chceme prostredie vykresľovať
for episode in range(EPISODES):
state = get_state(env.reset()) # Obnoví prostredie a vráti počiatočný stav
# Zisťujeme, či chceme vykresliť aktuálnu epizódu
if episode % SHOW_EVERY == 0:
render = True
else:
render = False
done = False
while not done: # Vykonávame ďalší krok, pokiaľ nedosiahneme terminálny stav
action = env.action_space.sample() # Vyberieme náhodnú akciu
# Samotné vykonanie kroku použitím akcie, ktorú sme zvolili
new_state, reward, done, info = env.step(action)
if render:
# Pre vyčistenie príkazového riadku (potrebné 'import os'):
# os.system('cls') vo Windows
# os.system('clear') v Linux
env.render() # Vykreslí prostredie v aktuálnom stave
env.close() # Po ukončení trénovania zavrieme prostredie
Po spustení môžeme vidieť vizualizáciu nášho prostredia a taxík robiaci náhodne pohyby. Vykonanie nového kroku env.step(action) nám vracia 4 hodnoty:
- new_state — nový stav, do ktorého sme prešli vykonaním akcie,
- reward — odmena získaná v novom stave,
- done — boolovská hodnota hovoriaca o tom, či sme už dosiahli terminálny stav,
- info — diagnostické informácie užitočné pri debugovaní (pre samotné učenie nie sú potrebné).
Tieto informácie môžeme teraz využiť pri samotnom učení a implementovať Q-learning. Najprv si však ešte pred začiatkom učenia nastavme konštanty, ktoré sú použité v samotnom vzorci aktualizácie tabuľky.
LEARNING_RATE = 0.1 # Intenzita učenia (alfa)
DISCOUNT = 0.99 # Faktor zľavy (gamma)
# Šanca na zvolenie náhodnej akcie namiesto tej najlepšej
# Chceme aby sa táto hodnota v priebehu epizód zmenšovala
epsilon = 1
EPSILON_MIN_VALUE = 0 # Minimálna hodnota epsilonu, pod ktorú nechceme ísť
START_EPSILON_DECAYING = 100 # Epizóda, pri ktorej chceme začať zmenšovať epsilon
END_EPSILON_DECAYING = EPISODES//2 # Epizóda, pri ktorej chceme ukončiť zmenšovanie
# Hodnota o ktorú chceme zmenšiť epsilon na konci každej epizódy
epsilon_decay_value = (
(epsilon - EPSILON_MIN_VALUE)
/ (END_EPSILON_DECAYING - START_EPSILON_DECAYING))
A teraz môžeme upraviť samotný cyklus s výpočtom a upravovaním Q hodnôt v tabuľke.
while not done:
# Exploration vs. exploitation
if np.random.random() > epsilon:
action = np.argmax(q_table[state]) # Výber najlepšej akcie podľa tabuľky
else:
action = env.action_space.sample() # Výber náhodnej akcie
new_state, reward, done, _ = env.step(action)
new_state = get_state(new_state)
if render:
# os.system('cls')
# os.system('clear')
env.render()
# Získanie najvyššej Q hodnoty v novom stave (Qmax)
max_future_q = np.max(q_table[new_state])
# Získanie Q hodnoty pre vykonanú akciu v starom stave
current_q = q_table[state + (action,)]
# Samotný vzorec vypočítania novej Q hodnoty
new_q = current_q + LEARNING_RATE*(reward + DISCOUNT*max_future_q - current_q)
# Aktualizovanie Q hodnoty v tabuľke pre starý stav a akciu novou hodnotou
q_table[state + (action,)] = new_q
# Nový stav sa stáva aktuálnym stavom a môžeme pokračovať v ďalšom kroku
state = new_state
# Znižovanie hodnoty epsilonu na konci epizódy
if END_EPSILON_DECAYING >= episode >= START_EPSILON_DECAYING:
epsilon -= epsilon_decay_value

Teraz už môžeme sledovať, ako sa náš agent postupne vyvíja. Zatiaľ čo jeho kroky pri epizóde 400 vyzerajú stále náhodne, v epizóde 800 už dokáže problém úspešne vyriešiť. V ďalších epizódach to vyzerá, že agent našiel aj najoptimálnejšie riešenie.
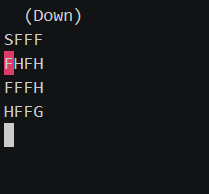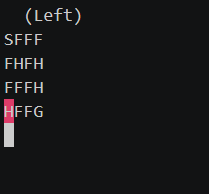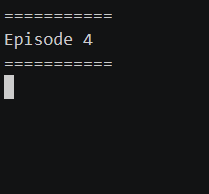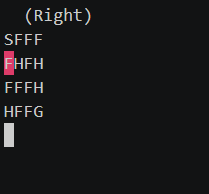
Teraz môžeme riešenie optimalizovať. Čo sa stane, keď upravíme niektorú z konštánt? Nájde agent riešenie, ak nastavíme epsilon od začiatku na 0? Ak ste to vyskúšali, mohli ste pozorovať, že agent dokáže nájsť riešenie aj bez náhodných akcií. Je to vďaka spôsobu odmeňovania v našom prostredí — za každý krok, ktorý agent vykoná. Prečo teda potrebujeme epsilon? Skúsme vyskúšať iné prostredie z knižnice Gym, napríklad Frozen Lake.
env = gym.make("FrozenLake-v0")
Ak ste epsilon nechali nastavený na 0, mohli ste si všimnúť, že agent ani po 1600 epizódach nespravil žiaden pokrok. Je to preto, lebo za každý krok, ktorý vykoná, dostane odmenu 0. Pozitívnu odmenu 1 dostane len po dosiahnutí cieľa. To znamená, že naša tabuľka sa nijako nezmení, pokiaľ agent nedôjde aspoň raz do cieľa. Preto nastavíme epsilon opäť na 1. Agent by sa teraz mal naučiť nájsť cestu do cieľa.
Stav prostredia typu Box
Ako sme si vraveli, Q-learning môžeme použiť len na prácu s diskrétnymi stavmi a akciami. Avšak môžeme sa pokúsiť riešiť niektoré problémy, kde je observation_space typu Box tak, že tieto hodnoty diskretizujeme, napríklad rozdelením celého intervalu na rovnaké časti — krabičky, ktorým vieme priradiť akúkoľvek hodnotu a zároveň ich uložiť v našej tabuľke. Vyskúšame si to na príklade prostredia Mountain Car.
env = gym.make("MountainCar-v0")
V tomto príklade máme auto nachádzajúce sa v doline. Cieľom je dostať ho do cieľa na vrchole kopca. Možné akcie sú pridať plyn doprava, doľava alebo neurobiť nič. Akcie sú síce v diskrétnej forme, no náš stav prostredia je už typu Box.
>>> env.observation_space
Box(2,)
To znamená, že náš stav prostredia predstavujú dve hodnoty, v tomto prípade pozícia a rýchlosť. Tie môžu byť akékoľvek reálne čísla na nejakom intervale. Maximum a minimum pre každé číslo si môžeme pozrieť spôsobom, ktorý sme spomínali vyššie.
>>> env.observation_space.high
array([0.6 , 0.07], dtype=float32)
>>> env.observation_space.low
array([-1.2 , -0.07], dtype=float32)
Poďme teda upraviť náš kód z predchádzajúcej kapitoly, aby vedel pracovať s týmito hodnotami.
if isinstance(env.observation_space, Discrete):
# Získanie veľkosti observation_space
OS_SIZE = [env.observation_space.n]
elif isinstance(env.observation_space, Box):
# Vytvoríme zoznam určujúci na koľko blokov chceme každý atribút rozdeliť
# Tento zápis bude všeobecne fungovať, no rozdeliť každý atribút prostredia
# na rovnaký počet blokov nemusí byť vždy optimálne
OS_SIZE = [20] * len(env.observation_space.high)
# V prípade MountainCar identický zápis - OS_SIZE = [20, 20]
# Vypočítame veľkosť jedného bloku pre každý atribút prostredia
OS_BLOCK_SIZE = ((env.observation_space.high - env.observation_space.low)
/ OS_SIZE)
if isinstance(env.action_space, Discrete):
# Získanie veľkosti action_space
AS_SIZE = [env.action_space.n]
def get_state(state):
if isinstance(env.observation_space, Discrete):
return (state,)
elif isinstance(env.observation_space, Box):
# Diskretizujeme každý atribút stavu podľa veľkosti bloku, ktorý sme
# vypočítali vyššie
discrete_state = (state - env.observation_space.low)/OS_BLOCK_SIZE
return tuple(discrete_state.astype(np.int))

Táto jednoduchá úprava nám umožní trénovať aj v prostredí, ktorého stav nie je v diskrétnej forme. Skúste zvýšiť počet epizód a sledovať, či sa autíčku podarí dostať na vrchol kopca.
Optimalizácia a sledovanie priebehu
Ak chceme nájsť tie najlepšie parametre, ktoré nás privedú k najrýchlejšiemu učeniu a nájdeniu optimálneho riešenia, je potrebné zvoliť si spôsob sledovania priebehu a úspešnosti nášho agenta počas učenia. Jednou z možností môže byť sledovanie niektorých informácií po istých častiach tréningu, napríklad každých 100 epizód. Sledovať môžeme napríklad priemerný počet krokov trvania epizód, priemernú získanú odmenu na konci epizód (relevantnosť závisí od spôsobu odmeňovania daného prostredia). V niektorých prostrediach môžeme sledovať, koľko pokusov bolo úspešných, napríklad v prostredí FrozenLake vieme, že za dosiahnutie cieľa je odmena +1. Pri našom prvom — taxíku — to bolo +20. Pri MountainCar dostávame podobne ako s taxíkom, za každý krok penalizáciu -1, no v tomto prípade aj pri dosiahnutí cieľa. Avšak prostredie nám poskytuje atribút goal_position určujúci pozíciu cieľa. Následne si dosiahnutie cieľa v každom kroku môžeme overiť takto:
if done and new_state[0] >= env.goal_position:
# Úspešne dokončená epizóda
Implementácie jednotlivých prostredí je možné preskúmať aj na GitHube. Napokon, ak sme našli vhodný spôsob určenia úspešnosti učenia nášho agenta, môžeme hľadať najlepšie nastavenia napríklad metódou Grid Search.
Zhrnutie
Reinforcement learning a neurónové siete sú jedným z náročnejších oborov informatiky. Algoritmus Q-learning opísaný a implementovaný v tomto článku môže byť dobrým začiatkom a vstupom do sveta umelej inteligencie. Knižnica Gym od OpenAI je skvelým nástrojom na výučbu RL a obsahuje mnoho ďalších prostredí, než len tie, ktoré sme si ukázali v tomto článku. Dobrou inšpiráciou pri písaní bol pre mňa článok na portáli LearnDataSci.
Ak vás zaujímajú novinky zo sveta umelej inteligencie, počítačového modelovania a simulácií, môžete sa pozrieť na YouTube kanál Two Minute Papers. Ak vás táto téma zaujala a neviete čo ďalej, môžete začať napríklad hľadaním návodov na tému deep RL alebo konkrétne algoritmu deep Q-learning ktorý sa už zaoberá využitím neurónových sietí a umožňuje riešiť oveľa zložitejšie problémy ako by sme dokázali s obyčajným Q-learning.
Celý skript z tohto článku si môžete pozrieť na GitLabe.